Wait But Why - IA - Partie 2
Note du traducteur
Le texte traduit ici est issu du blog original de Tim Urban de 2015. Il s’agit d’une traduction non officielle, mais faite avec l’accord de l’auteur.
Avec l’avènement des LLM, les voix avertissant sur les dangers de l’IA sont devenues plus nombreuses et plus pressantes. Nous donnons une perspective actualisée de cet essai de WaitButWhy dans un article sur notre blog.
La Révolution de l’IA : Notre Immortalité ou Notre Extinction
27 janvier 2015 Par Tim Urban – traduction de Mai 2025
Note : Ceci est la Partie 2 d’une série en deux parties sur l’IA. La Partie 1 est ici.
PDF en anglais : Nous avons créé un PDF super classe de cet article pour l’impression et la lecture hors ligne. Achetez-le ici. (Ou consultez-en un aperçu.)
Nous sommes confrontés à un problème potentiellement extrêmement difficile à résoudre, sans aucune idée du délai imparti, et dont pourrait dépendre l’avenir de l’humanité tout entière. - Nick Bostrom
Bienvenue dans la Partie 2 de la série intitulée “Attends-voir, comment c’est possible de lire un truc pareil, je ne comprends pas pourquoi c’est pas au centre de toutes les conversations”.
La Partie 1 a commencé de manière assez innocente, à aborder la question de l’Intelligence Artificielle Étroite, ou ANI en anglais pour Artificial Narrow Intelligence (IA spécialisée dans une tâche précise comme trouver des itinéraires ou jouer aux échecs), et comment elle est devenue omniprésente dans le monde actuel. Nous avons ensuite examiné pourquoi il était si difficile de passer de l’ANI à l’Intelligence Artificielle Générale, ou AGI pour Artificial General Intelligence (IA au moins aussi intellectuellement douée qu’un être humain, dans tous les domaines), et nous avons discuté de la façon dont le rythme exponentiel des avancées technologiques que nous avons observé par le passé suggère que l’AGI pourrait n’être pas aussi lointaine qu’il y paraît. J’ai terminé la Partie 1 en vous assénant sans crier gare le fait que lorsque nos machines atteindront un niveau d’intelligence comparable à celui des humains, voici ce qu’elles pourraient faire dans la foulée :




On s’est donc retrouvé à fixer l’écran comme deux ronds de flan, confrontés au concept hardcore de la superintelligence artificielle, ou ASI pour Artificial Super Intelligence (une IA bien plus intelligente que n’importe quel humain, sur tous les plans), essayant de comprendre ce qu’on était censé ressentir en pensant à tout ça .1 fake content 1 fake content ← cliquez sur les 2
Avant d’entrer dans le vif du sujet, rappelons-nous ce que signifierait pour une machine d’être superintelligente.
Une distinction clé réside dans la différence entre la vitesse et la qualité de la superintelligence. Souvent, la première chose à laquelle on pense quand on imagine un ordinateur super intelligent, c’est un ordinateur aussi intelligent qu’un humain mais qui peut penser beaucoup, beaucoup plus vite2 fake content — on s’imaginerait une machine qui pense comme un humain, mais mille fois plus rapidement, ce qui signifie qu’elle pourrait résoudre en cinq minutes ce qui prendrait une décennie à un humain.
Cela paraît impressionnant, et l’ASI penserait effectivement beaucoup plus vite que n’importe quel humain — mais ce qui créerait vraiment l’écart, ce serait son avantage en termes de qualité d’intelligence, qui est quelque chose de complètement différent. Ce qui rend les humains tellement plus intellectuellement capables que les chimpanzés n’est pas une différence de vitesse de pensée — c’est que les cerveaux humains contiennent plusieurs modules cognitifs sophistiqués qui permettent des choses comme des représentations linguistiques complexes, la planification à long terme ou le raisonnement abstrait, que les cerveaux des chimpanzés ne possèdent pas. Accélérer le cerveau d’un chimpanzé des milliers de fois ne l’élèverait pas à notre niveau — même en dix ans, il ne serait pas capable de comprendre comment utiliser un ensemble d’outils spécifiques pour assembler un modèle complexe, chose qu’un humain pourrait boucler en quelques heures. Il existe des pans entiers des fonctions cognitives humaines qu’un chimpanzé ne sera tout simplement jamais capable de comprendre, quels que soient ses efforts.
Mais ce n’est pas seulement qu’un chimpanzé ne peut pas faire ce que nous faisons, c’est que son cerveau est incapable ne serait-ce que de saisir que ces fonctions cognitives existent — un chimpanzé peut se familiariser avec le concept d’être humain et de gratte-ciel, mais il ne sera jamais capable de comprendre que le gratte-ciel a été construit par des humains. Dans son monde, tout ce qui atteint cette taille-là fait partie de la nature, point final, et non seulement il est incapable de construire un gratte-ciel, mais il est également incapable de comprendre que quelqu’un puisse construire un gratte-ciel. Ça, c’est ce que l’on obtient avec une petite différence en matière de qualité d’intelligence.
Et dans l’échelle des niveaux d’intelligence dont nous parlons aujourd’hui, ou même dans la plage beaucoup plus restreinte sur laquelle se situent les créatures biologiques, l’écart qualitatif d’intelligence entre le chimpanzé et l’humain est minuscule. Dans un article précédent, j’ai représenté la gamme des capacités cognitives biologiques à l’aide d’un escalier :3 fake content

Pour comprendre l’importance fondamentale de l’advenue d’une machine superintelligente, imaginez-en une sur la marche vert foncé deux marches au-dessus des humains. Cette machine serait seulement légèrement superintelligente, mais sa capacité cognitive supérieure par rapport à nous serait aussi vaste que l’écart chimpanzé-humain que nous venons de décrire. Et tout comme le chimpanzé est incapable de comprendre que des gratte-ciels peuvent être construits, nous ne serons jamais capables de commencer à comprendre les choses qu’une machine sur la marche vert foncé peut faire, même si la machine essayait de nous l’expliquer — sans même parler de faire ces choses nous-mêmes. Et ça, ce n’est que deux marches au-dessus de nous. Une machine sur l’avant-dernière marche de cet escalier serait pour nous ce que nous sommes pour les fourmis — elle pourrait essayer pendant des années de nous enseigner la plus simple parcelle de ce qu’elle sait, l’entreprise serait vouée à l’échec.
Mais le type de superintelligence dont nous parlons aujourd’hui est bien au-delà de tout ce qui figure sur cet escalier. Dans le scénario d’une explosion d’intelligence — où plus une machine devient intelligente, plus elle est capable d’accroître rapidement sa propre intelligence, jusqu’à ce qu’elle commence à monter en flèche — une machine pourrait mettre des années pour passer de la marche du chimpanzé à celle juste au-dessus, mais peut-être seulement quelques heures pour monter une marche une fois qu’elle se trouve sur la marche vert foncé deux marches au-dessus de nous, et lorsqu’elle sera dix marches au-dessus de nous, elle pourrait sauter les marches quatre à quatre à chaque seconde qui passe. C’est pourquoi nous devons prendre conscience du fait qu’il est tout à fait possible que très peu de temps après qu’on aura eu dans les journaux un gros titre du genre “C’est une première : une machine atteint le niveau d’intelligence générale humaine”, nous pourrions nous retrouver à coexister sur Terre avec quelque chose qui se trouve ici sur l’escalier (ou peut-être un million de fois plus haut) :
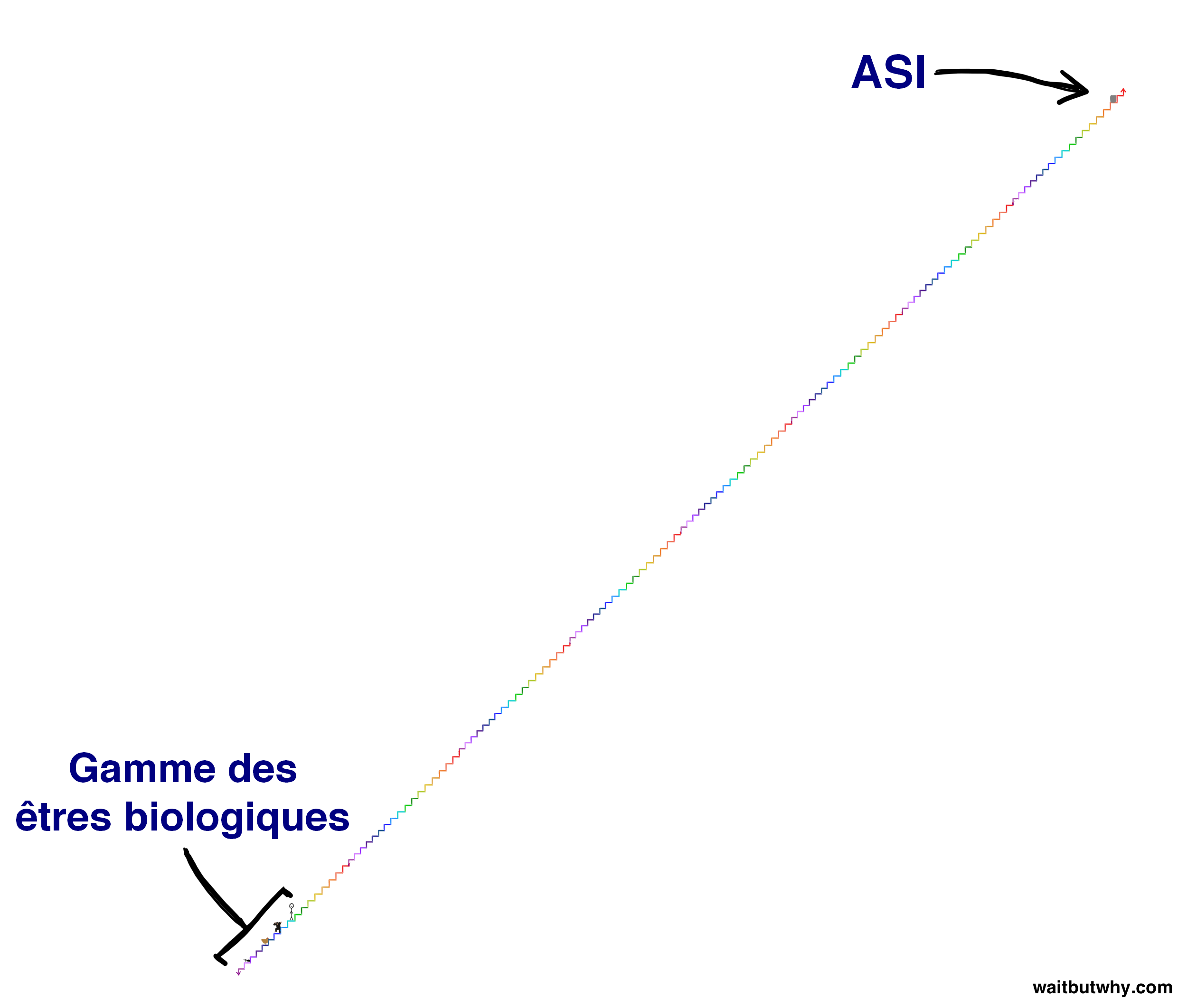
Et puisque nous venons d’établir qu’il est vain d’essayer de comprendre la puissance d’une machine qui se trouve deux marches au-dessus de nous, disons de façon très nette et une fois pour toutes qu’il n’y a aucun moyen de savoir ce que fera l’ASI ni quelles en seront les conséquences pour nous. Quiconque prétend le contraire ne comprend pas ce que signifie la superintelligence.
L’évolution a fait progresser le cerveau biologique lentement et progressivement sur des centaines de millions d’années et, en ce sens, si les humains donnent naissance à une ASI, notre espèce foulera aux pieds de façon radicale le processus de l’évolution. Ou peut-être que cela fait partie de l’évolution - peut-être que la façon dont l’évolution fonctionne est que l’intelligence progresse de plus en plus jusqu’à ce qu’elle atteigne le niveau où elle est capable de créer une machine superintelligente, et que ce niveau, c’est un peu comme le fil déclencheur d’une mine qui va provoquer une explosion mondiale, explosion qui va changer la donne et décider d’un nouvel avenir pour tous les êtres vivants :
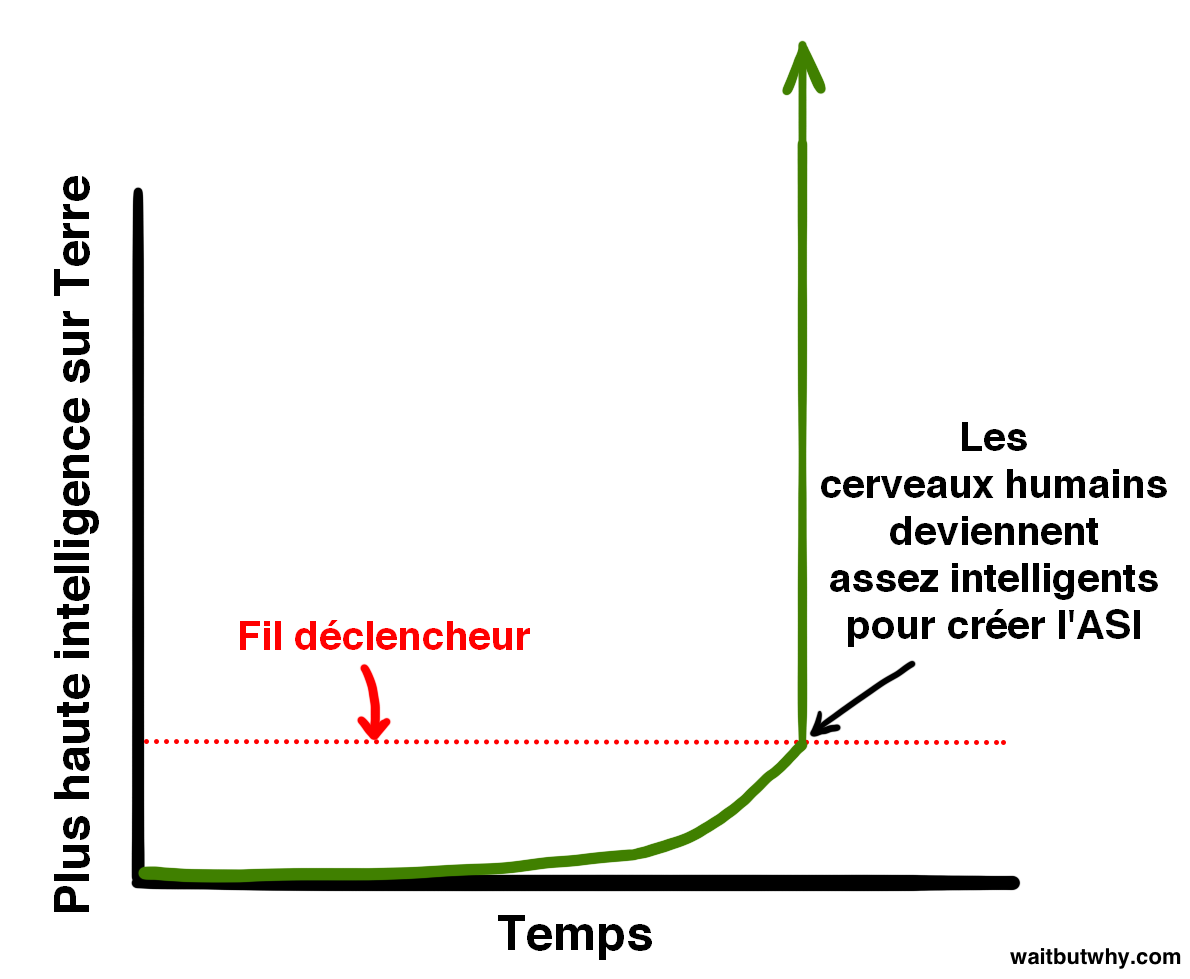
Et pour des raisons que nous aborderons plus tard, une grande partie de la communauté scientifique croit que la question n’est pas tant de savoir si nous allons déclencher la mine en marchant sur le fil de fer, mais quand. Une idée plutôt dingue.
Alors, ça nous mène où tout ça ?
Personne au monde, et surtout pas moi, ne peut vous dire ce qui se passera lorsque nous marcherons sur ce fil. Mais Nick Bostrom, philosophe à Oxford et penseur de l’IA de tout premier plan, croit que l’on peut schématiquement résumer toutes les retombées probables en les classant dans deux grandes catégories.
Premièrement, en regardant l’histoire, on constate que la vie fonctionne ainsi : des espèces apparaissent, existent pendant un certain temps, et après un moment, inévitablement, elles tombent de la poutre de l’existence sur laquelle elles étaient en équilibre et s’écrasent : c’est l’extinction —
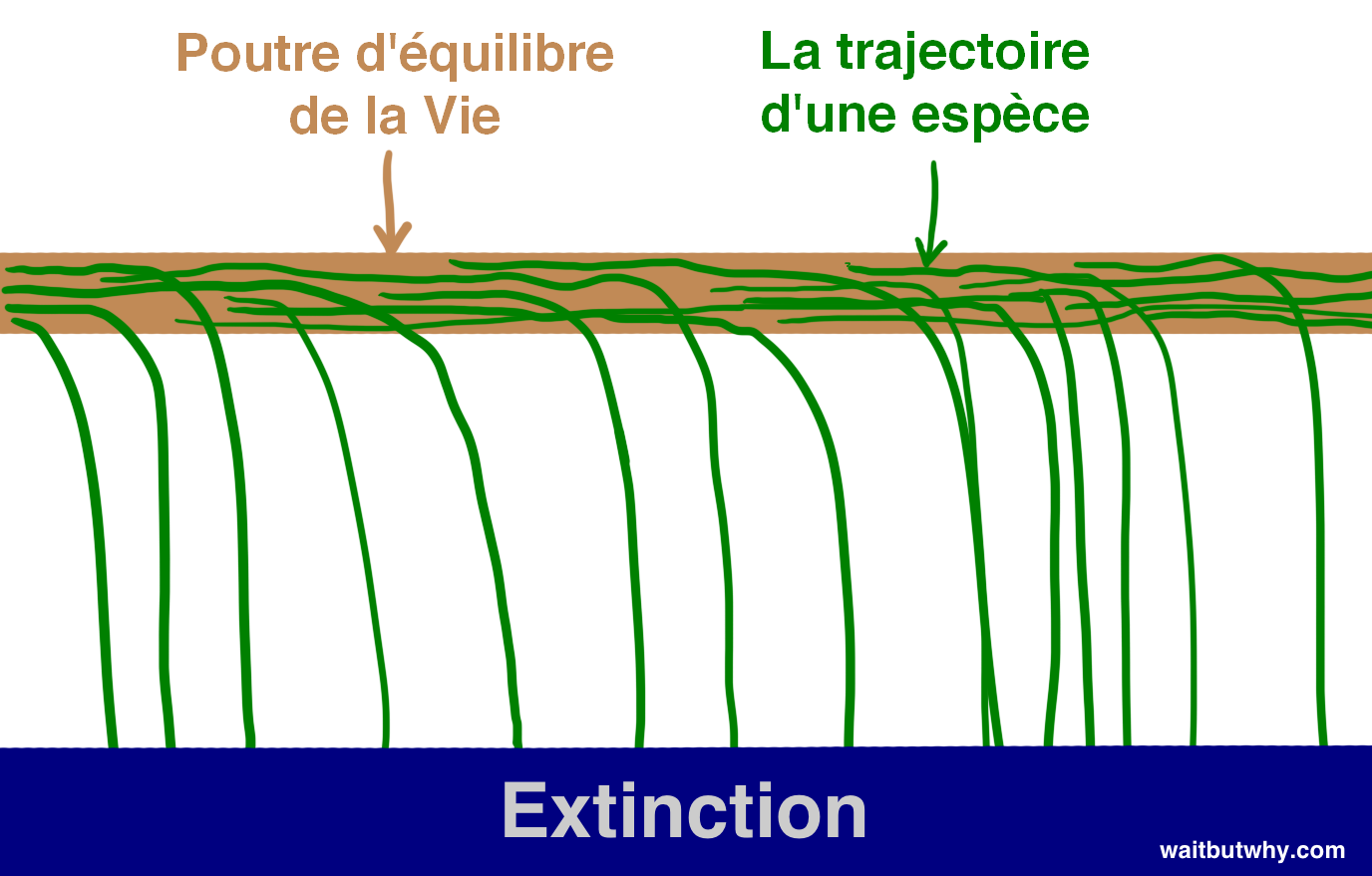
La loi selon laquelle “toutes les espèces finissent par s’éteindre” a été presque aussi fiable dans l’histoire que celle qui dit que “tous les humains finissent par mourir”. Jusqu’à présent, 99,9 % des espèces sont tombées de la poutre, et il semble assez clair que si une espèce avance en chancelant sur la poutre, ce n’est qu’une question de temps avant qu’une autre espèce, un coup de vent de la nature, ou un astéroïde venant tout à coup secouer la poutre, ne la fasse tomber. Bostrom appelle l’extinction un état d’attraction — un endroit dans lequel toutes les espèces risquent d’être précipitées et d’où aucune espèce ne revient jamais.
Et bien que la plupart des scientifiques que j’ai rencontrés admettent que l’ASI pourrait précipiter les humains vers leur extinction, beaucoup croient également que, utilisées à bon escient, les capacités de l’ASI pourraient être utilisées pour amener les individus, et l’espèce dans son ensemble, à un second état d’attraction — l’immortalité de l’espèce. Bostrom croit que l’immortalité de l’espèce exerce une force tout aussi attractrice que l’extinction de l’espèce, c’est-à-dire que si nous y arrivons, nous serons sauvés de l’extinction pour toujours — nous aurons vaincu la mortalité et le hasard. Donc, même si toutes les espèces jusqu’à présent sont tombées de la poutre et ont atterri dans l’état d’extinction, Bostrom croit que la poutre a deux côtés et que rien sur Terre n’a encore été suffisamment intelligent pour comprendre comment tomber de l’autre côté.
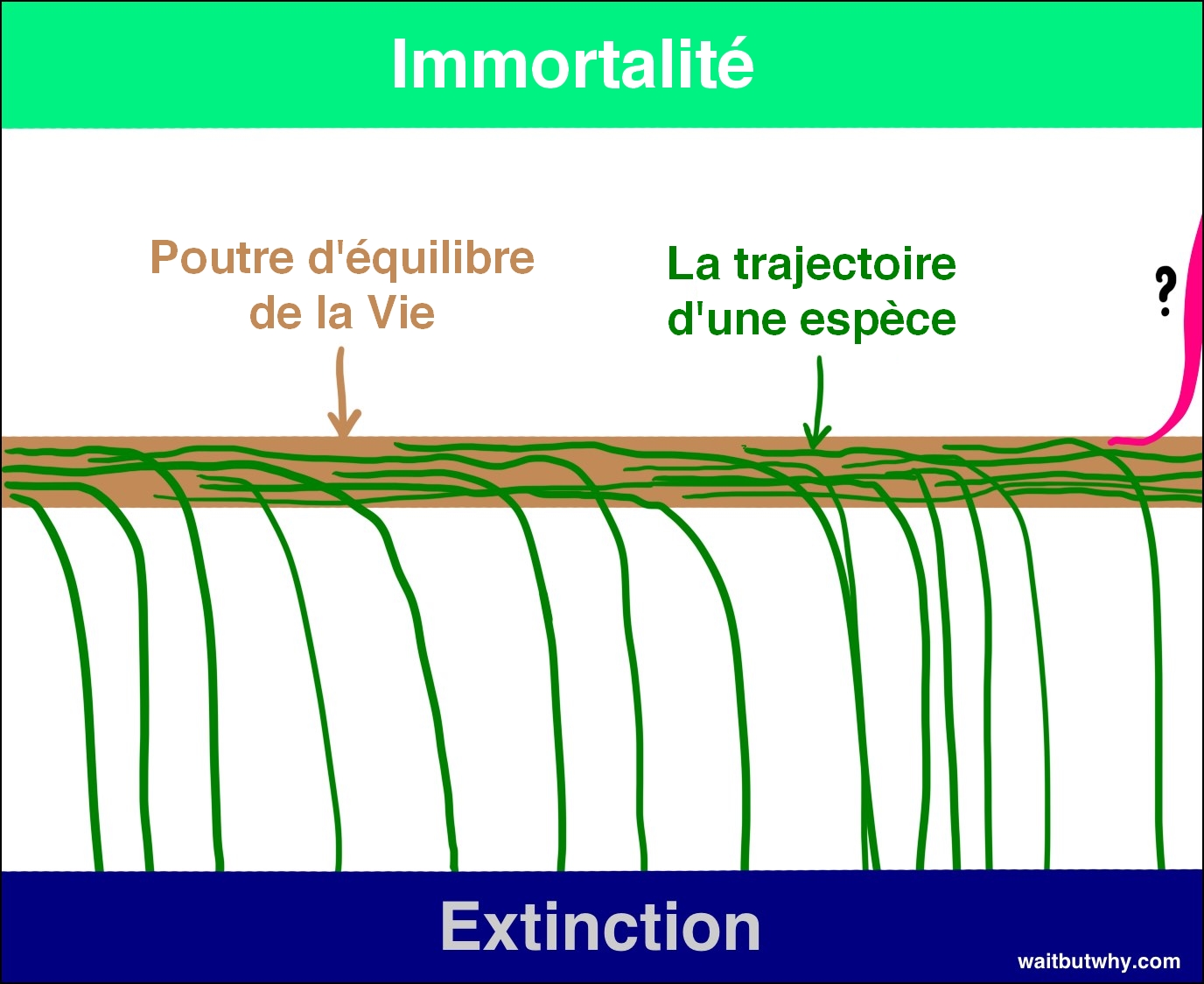
Si Bostrom et d’autres ont raison, et d’après tout ce que j’ai lu, il semble qu’ils pourraient vraiment avoir raison, ça nous fait deux idées assez hallucinantes à digérer :
1) L’avènement de l’ASI pourrait, pour la première fois, permettre à une espèce de se placer du côté de l’immortalité sur la poutre.
2) L’avènement de l’ASI aura un impact si incroyablement spectaculaire qu’il pourrait bien faire basculer l’espèce humaine d’un côté ou de l’autre de la poutre.
Il se peut très bien que lorsque l’évolution déclenchera le fil déclencheur, elle coupe définitivement la relation qui unit les humains avec la poutre et crée un monde nouveau, avec ou sans humains.
On peut penser que la seule question que nous, humains, devrions nous poser aujourd’hui c’est : Quand allons-nous passer le point de non-retour et de quel côté de la poutre atterrirons-nous quand cela arrivera ?
Personne au monde ne connaît la réponse à l’une ni à l’autre de ces questions, mais beaucoup des plus gros cerveaux sur terre y réfléchissent depuis des dizaines d’années. Nous passerons le reste de ce texte à explorer les idées qu’ils ont eu.
Commençons par la première partie de la question : Quand allons-nous passer le point de non-retour ?
C’est-à-dire, combien de temps avant qu’une machine n’atteigne la superintelligence ?
Chose peu étonnante, les opinions varient considérablement et cette question fait l’objet d’un débat passionné parmi les scientifiques et les penseurs. Beaucoup, comme le professeur Vernor Vinge, le scientifique Ben Goertzel, le co-fondateur de Sun Microsystems Bill Joy, ou, le plus célèbre d’entre eux, l’inventeur et futurologue Ray Kurzweil, sont d’accord avec l’expert en apprentissage automatique Jeremy Howard quand il présente ce graphique lors d’une conférence TED :
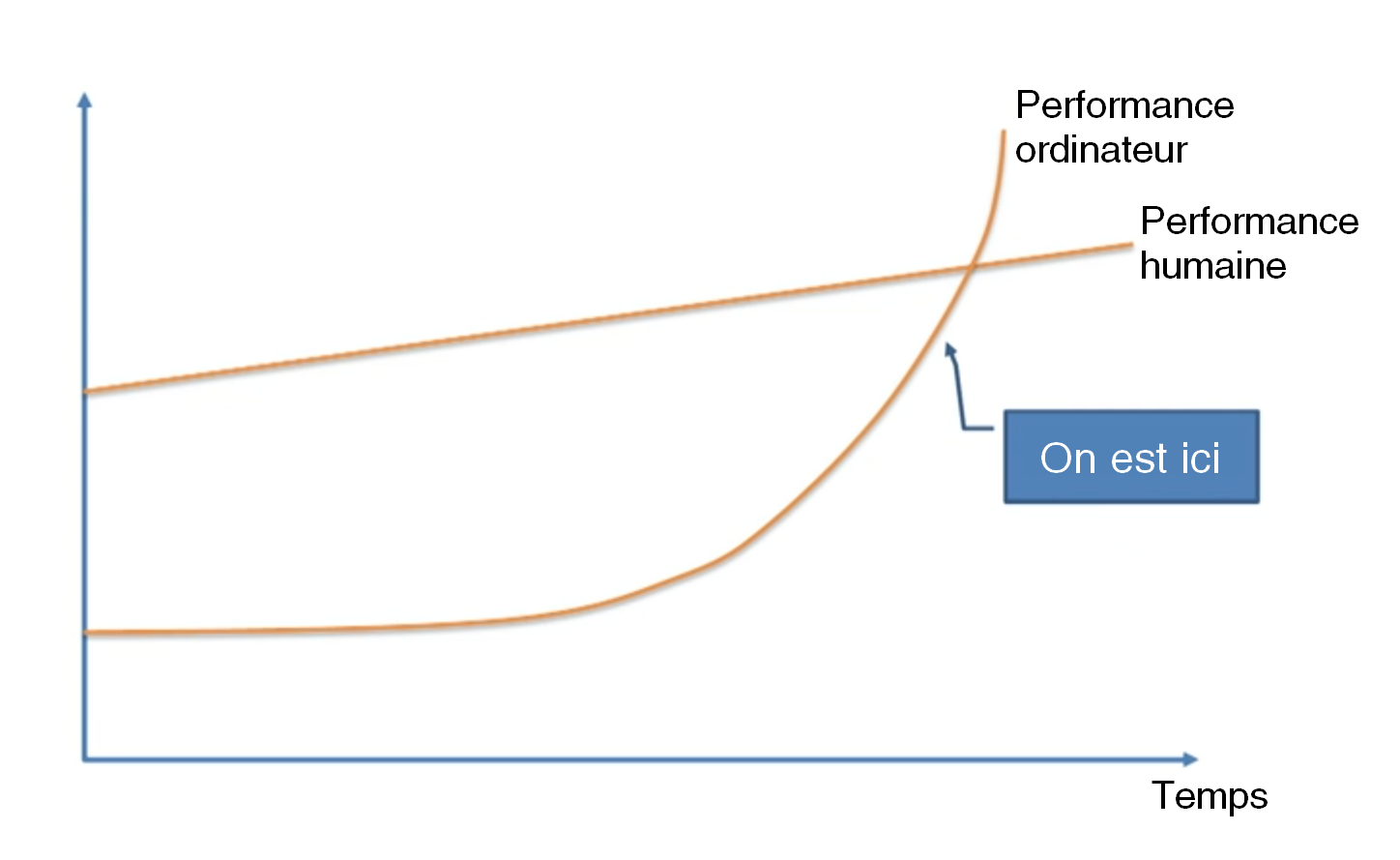
Ces personnes adhèrent à l’idée que cela va arriver bientôt - qu’une croissance exponentielle est à l’œuvre et que l’apprentissage automatique, qui pour l’instant se contente de grignoter du terrain sur nous, nous dépassera complètement dans les prochaines décennies.
D’autres, comme le co-fondateur de Microsoft Paul Allen, le psychologue et chercheur Gary Marcus, l’informaticien de la NYU Ernest Davis, et l’entrepreneur de la tech Mitch Kapor, sont d’avis que des penseurs comme Kurzweil sous-estiment considérablement l’ampleur du défi et croient que nous ne sommes pas vraiment si proches du point de non-retour.
Le camp de Kurzweil rétorquerait que la seule vraie sous-estimation, c’est celle de la croissance exponentielle, et ils compareraient les sceptiques à ceux qui, en 1985, observaient la lente croissance des premiers bourgeons d’Internet et affirmaient qu’il était impossible que ces prémices aient un impact significatif dans le futur proche.
Les sceptiques pourraient répliquer à leur tour que les progrès nécessaires pour faire des avancées en intelligence deviennent également exponentiellement plus difficiles à chaque étape successive, ce qui annulerait la nature exponentielle habituelle du progrès technologique. Et ainsi de suite.
Un troisième camp, dans lequel se range Nick Bostrom, considère qu’aucun des deux groupes n’a de raison d’affirmer quoi que ce soit sur le calendrier et admet à la fois que A) cela pourrait absolument se produire dans un avenir proche et B) qu’il n’y a aucune garantie à ce sujet : cela pourrait tout aussi bien prendre beaucoup plus de temps.
D’autres encore, comme le philosophe Hubert Dreyfus, pensent que ces trois groupes sont naïfs de croire qu’il existe un point de non-retour, soutenant l’idée qu’il est plus probable que l’ASI ne soit jamais réellement atteinte.
Alors, que ressort-il de la confrontation de toutes ces opinions ?
En 2013, Vincent C. Müller et Nick Bostrom ont mené une enquête qui a posé la question suivante à des centaines d’experts en IA lors d’une série de conférences : “Pour répondre à cette question, supposez que l’activité scientifique humaine continue sans accident majeur. Pour quelle année estimez-vous l’advenue probable (soit à 10 % , 50 % ou 90 %) d’une telle AGI4 fake content ?” On leur demandait une estimation optimiste de cette date (où ils estimaient à 10 % la chance d’avoir une AGI), une estimation réaliste (l’année où ils pensaient que nous avions 50 % de chances d’atteindre l’AGI - c’est-à-dire l’année après laquelle, selon eux, il serait davantage probable qu’improbable d’avoir une AGI), et une estimation prudente (la première année pour laquelle ils pouvaient affirmer avec 90 % de certitude que nous aurions une AGI). Le résumé concis de ces sondages est le suivant :2 fake content
Année médiane optimiste (probabilité de 10 %) : 2022
Année médiane réaliste (probabilité de 50 %) : 2040
Année médiane pessimiste (probabilité de 90 %) : 2075
Ainsi, le participant médian pense qu’il est plus probable qu’improbable que nous ayons une AGI dans 25 ans. La réponse médiane à 90 % en 2075 signifie que si vous êtes adolescent en ce moment, le répondant médian, ainsi que plus de la moitié du groupe d’experts en IA, est presque certain que l’AGI sera atteinte au cours de votre vie.
Une étude distincte, menée récemment par l’essayiste James Barrat lors de la conférence annuelle sur l’AGIde Ben Goertzel, a fait abstraction des pourcentages et a simplement demandé quand les participants pensaient que l’AGI serait atteinte - d’ici 2030, d’ici 2050, d’ici 2100, après 2100, ou jamais. Les résultats sont les suivants :3 fake content
D’ici 2030 : 42 % des répondants
D’ici 2050 : 25 %
D’ici 2100 : 20 %
Après 2100 : 10 %
Jamais : 2 %
Assez proche des résultats de Müller et Bostrom. Dans l’enquête de Barrat, plus des deux tiers des participants pensent que l’AGI sera là d’ici 2050 et un peu moins de la moitié prévoient l’AGI dans les 15 prochaines années. Ce qui est également frappant, c’est que seulement 2 % de ceux interrogés pensent que l’AGI ne fait partie de notre avenir.
Mais ce n’est pas l’AGI qui constitue le point de non-retour, c’est l’ASI. Alors quand les experts pensent-ils que nous atteindrons l’ASI ?
Müller et Bostrom ont également demandé aux experts à quelle probabilité ils évaluent l’obtention de l’ASI A) dans les deux ans suivant l’obtention de l’AGI (c’est-à-dire une explosion d’intelligence presque immédiate), et B) dans les 30 ans. Voici les résultats :4 fake content
La réponse médiane ne donne qu’une probabilité de 10 % à une transition AGI → ASI rapide (2 ans), mais une probabilité de 75 % à une transition plus longue de 30 ans ou moins.
Ces données ne nous donnent pas la durée de transition que le participant médian aurait estimée probable à 50 %, mais à des fins d’estimation au doigt mouillé, en se basant sur les deux réponses ci-dessus, admettons qu’il aurait dit 20 ans. Ainsi, l’opinion médiane - celle qui se situe au centre de la communauté des experts en IA - considère que l’estimation la plus réaliste pour atteindre le point de non-retour de l’ASI est [la prédiction de 2040 pour l’AGI + notre estimation de transition de 20 ans de l’AGI à la ASI] = 2060.
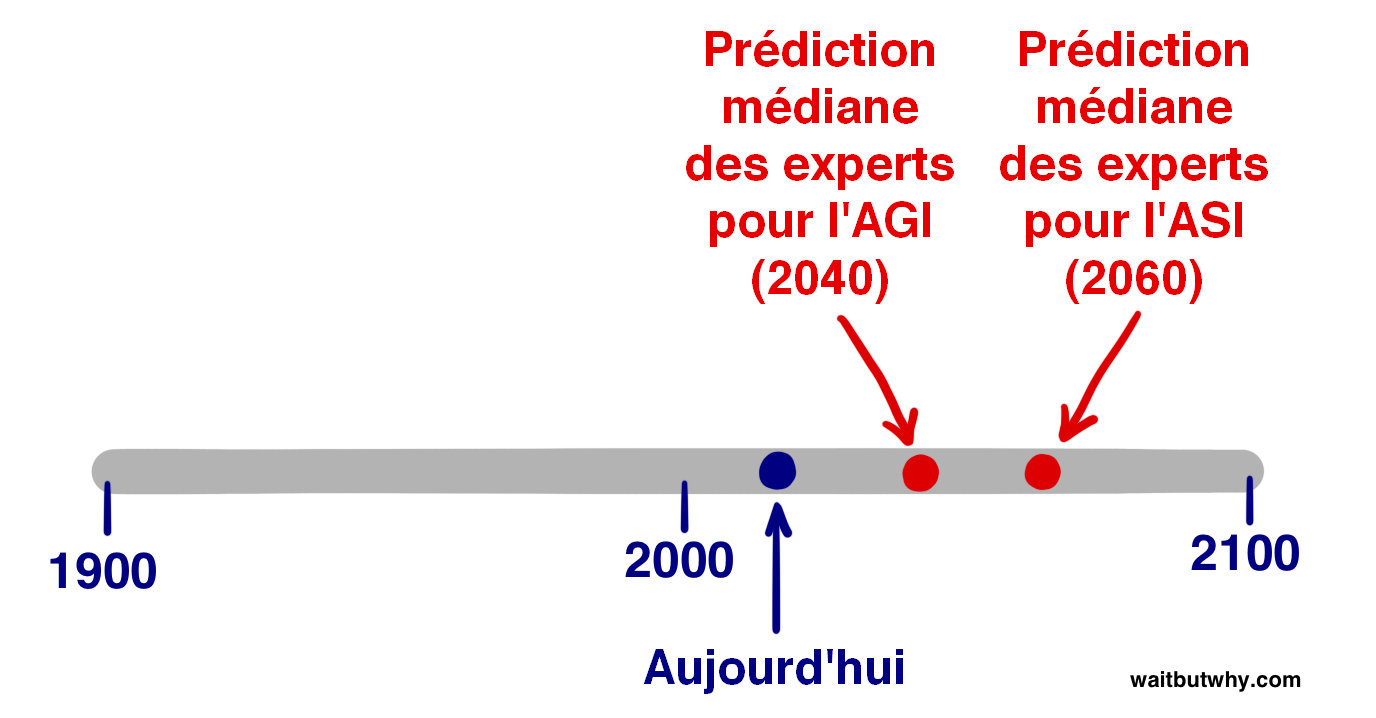
Bien sûr, toutes ces statistiques sont spéculatives, et elles ne représentent que l’opinion la plus consensuelle de la communauté d’experts en IA, mais elles nous indiquent qu’une grande partie des personnes qui ont le plus de connaissances sur ce sujet s’accorderaient sur 2060 comme une estimation très raisonnable pour l’arrivée d’une ASI potentiellement porteuse de bouleversements mondiaux. Dans tout juste 45 ans.
Passons maintenant à la deuxième partie de la question : lorsque nous atteindrons le point de non-retour, de quel côté de la poutre tomberons-nous ?
La superintelligence sera porteuse d’un pouvoir considérable - la question critique pour nous est :
Qui (humain ou entité) contrôlera ce pouvoir, et quelle sera sa motivation ?
Répondre à cette question, c’est déterminer si l’ASI sera une évolution extraordinairement top, impensablement pourrie, ou entre les deux.
Bien sûr, la communauté d’experts est à nouveau très divisée et se répand en débats passionnés sur la réponse à cette question. L’enquête de Müller et Bostrom a demandé aux participants d’attribuer une probabilité aux impacts potentiels de l’AGI sur l’humanité et a constaté que la réponse moyenne était qu’il y avait 52 % de chance que le résultat soit bon ou extrêmement bon et 31 % de chance qu’il soit mauvais ou extrêmement mauvais. Pour un résultat relativement neutre, la probabilité moyenne n’était que de 17 %. En d’autres termes, les personnes qui ont le plus de connaissances à ce sujet sont assez certaines que ce sera un événement majeur. Il est également intéressant de noter que ces chiffres concernent l’avènement de l’AGI — si la question portait sur l’ASI, j’imagine que le pourcentage neutre serait encore plus bas.
Avant de nous plonger davantage dans cette partie de la question concernant les résultats positifs ou négatifs, combinons les notions de “quand est-ce que ça va se produire ?” et “est-ce que ce sera bon ou mauvais ?” dans un graphique qui englobe les points de vue de la plupart des experts concernés :
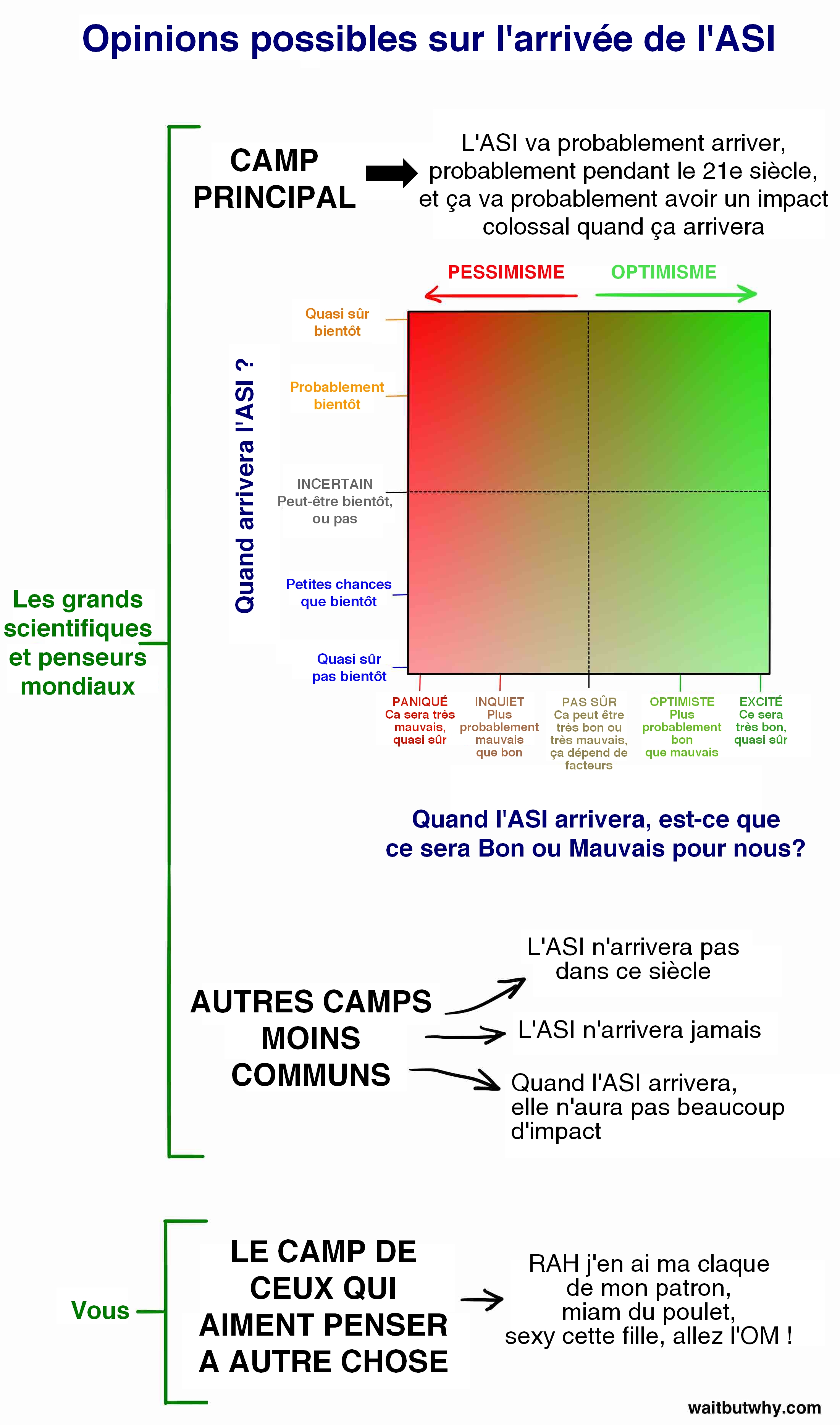
Nous parlerons plus en détail du Camp Principal dans un instant, mais d’abord – où est-ce que vous vous situez, vous ? En fait, je sais où, car moi aussi c’est là que j’étais avant de commencer mes recherches sur ce sujet. Voici quelques raisons pour lesquelles la plupart des gens ne pensent pas vraiment à cette question :
Comme je l’ai dit dans la Partie 1, les films ont vraiment brouillé les choses en présentant des scénarios d’IA irréalistes qui nous donnent grosso modo l’impression que l’IA, ce n’est pas du sérieux. James Barrat compare la situation à notre réaction si l’Organisation Mondiale de la Santé émettait une alerte aux risques sérieux d’attaques de vampires. 5 fake content
Les humains ont du mal à croire quelque chose jusqu’à ce qu’ils en voient la preuve. Je suis sûr que les informaticiens en 1988 parlaient régulièrement de l’importance qu’allait sans doute avoir Internet, mais les gens ne pensaient probablement pas vraiment que cela allait changer leur vie avant que cela se produise concrètement. C’est en partie parce que les ordinateurs ne pouvaient pas faire ce genre de choses en 1988, alors les gens regardaient leur ordinateur en se disant : ”Vraiment ? Ce truc-là, ça va changer ma vie ?” Leur imagination était limitée à ce que leur expérience personnelle leur avait appris de ce qu’était un ordinateur, ce qui rendait très difficile le fait de s’imaginer clairement ce que les ordinateurs pourraient devenir. La même chose se produit maintenant avec l’IA. Nous entendons dire qu’elle va être cruciale, mais comme cela ne s’est pas encore produit, et en raison de notre expérience avec des IA relativement peu puissantes dans notre monde actuel, nous avons du mal à vraiment croire que cela va changer notre vie de façon spectaculaire. Et c’est contre ce genre de préjugés que les experts se battent en essayant désespérément d’attirer notre attention émoussée par le bruit diffus de la vie quotidienne qui nous amène à ne voir que ce qui nous concerne.
Même si nous y croyions pour de vrai - combien de fois aujourd’hui avez-vous pensé au fait que vous allez passer la majeure partie de l’éternité à ne pas exister ? Pas beaucoup, hein ? Même si c’est un fait bien plus dingue que n’importe laquelle de vos activités de la journée ? C’est parce que nos cerveaux se concentrent normalement sur les petites choses de la vie quotidienne, quelle que soit la situation de ouf qui nous attend sur le long terme. C’est tout simplement notre nature.
L’un des objectifs de ces deux articles est de vous faire sortir du Camp de Ceux Qui Préfèrent Penser à Autre Chose et de vous faire entrer dans l’un des camps d’experts, ne serait-ce qu’en vous tenant à l’intersection des deux lignes pointillées du carré ci-dessus, dans un état d’incertitude totale.
Pendant mes recherches, je suis tombé sur des dizaines d’opinions différentes sur ce sujet, mais j’ai rapidement remarqué que les opinions de la plupart des gens se situaient quelque part dans ce que j’ai appelé le Camp Principal, et en particulier, plus des trois quarts des experts se situaient dans deux Sous-camps à l’intérieur du Camp Principal :
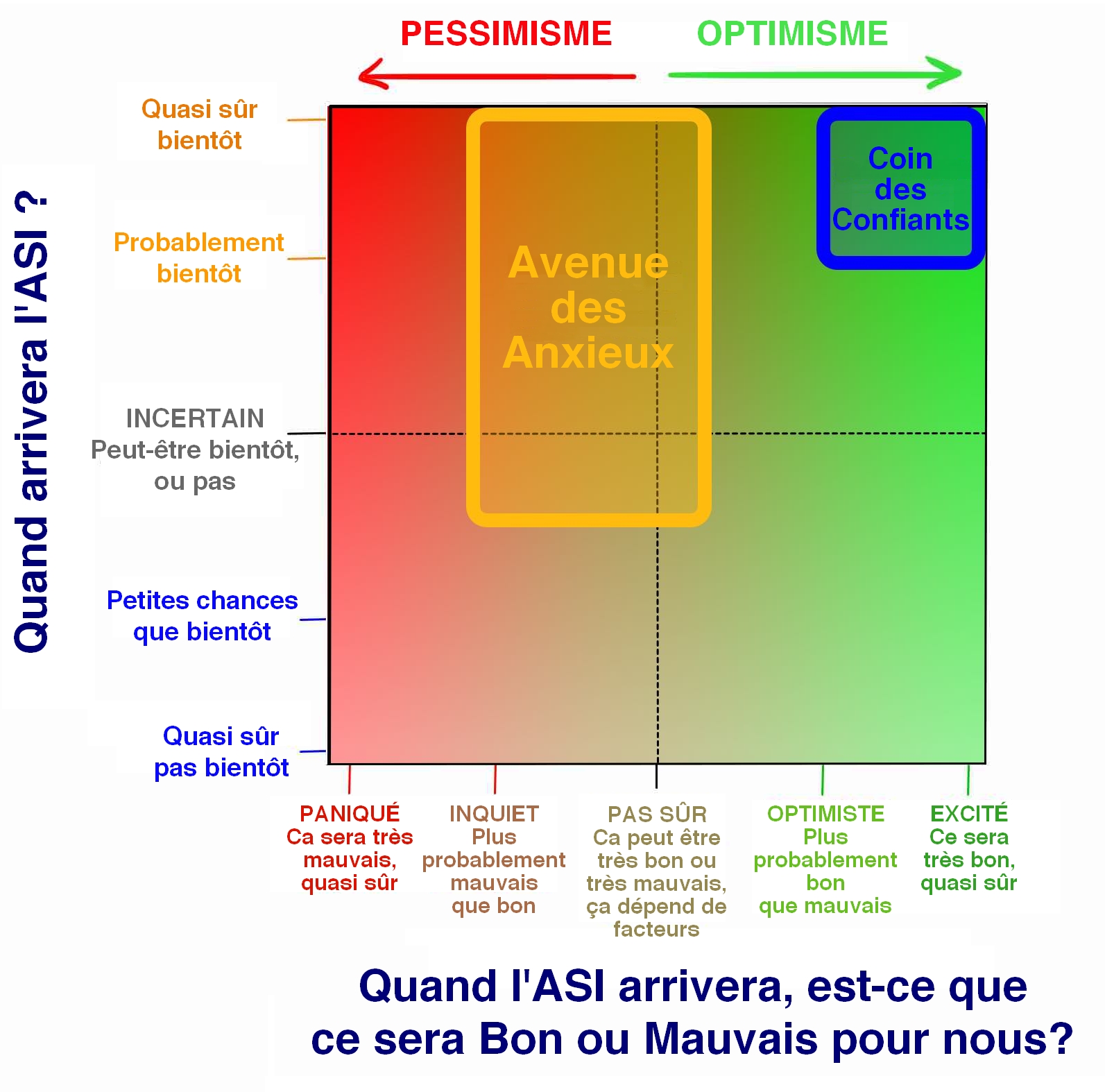
Plongeons à présent en profondeur dans chacun de ces deux camps. Commençons par le camp le plus sympa -
Pourquoi l’avenir pourrait être l’accomplissement de notre plus grand rêve
Au fur et à mesure de mes découvertes sur le monde de l’intelligence artificielle, j’ai découvert qu’étonnamment, beaucoup de gens appartenaient à ce camp.
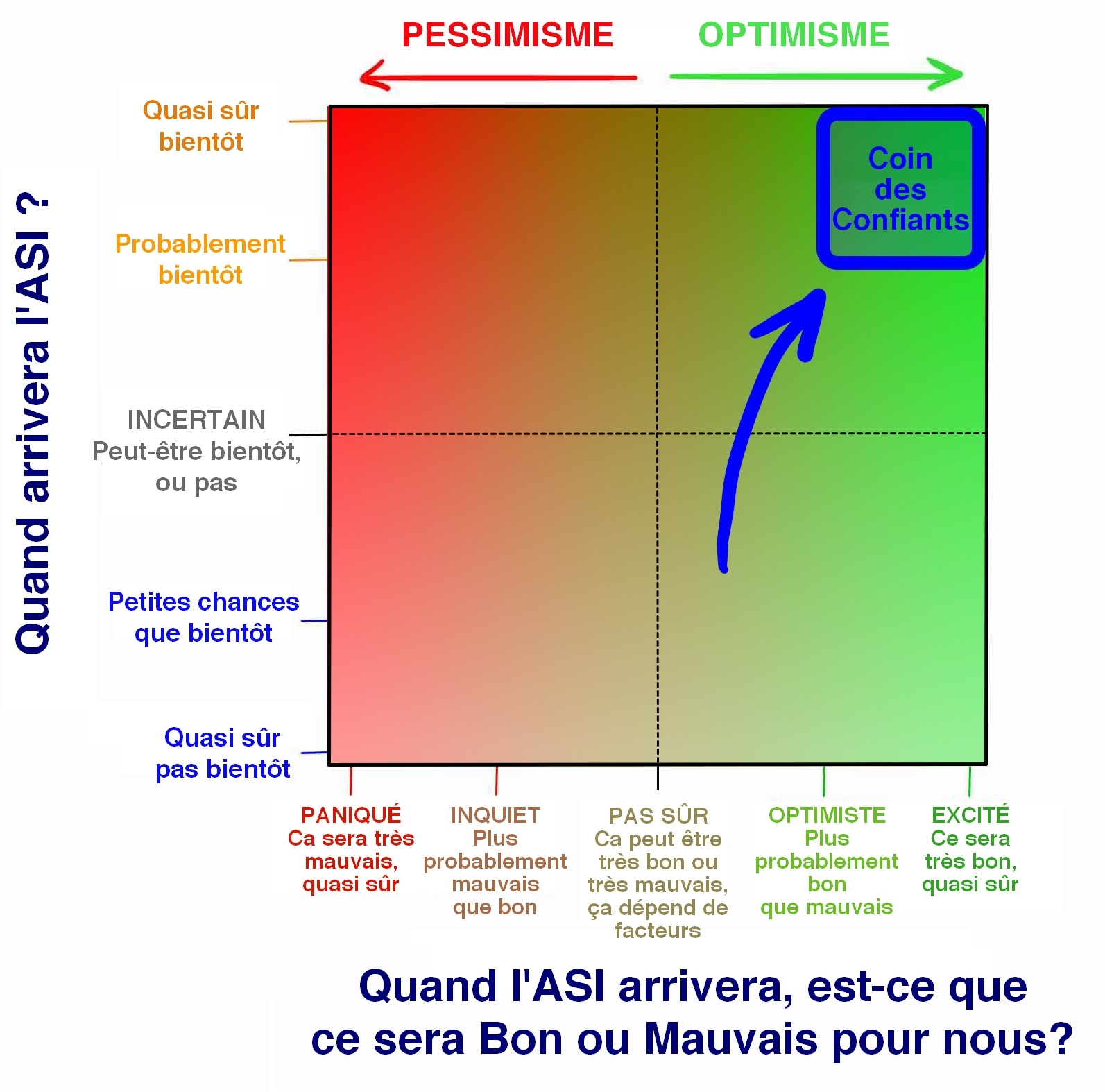
Les gens qui se rangent dans le Coin des Confiants débordent d’enthousiasme. Ils ont les yeux rivés sur le côté sympa de la poutre et sont convaincus que c’est là que nous allons tous atterrir. Pour eux, l’avenir représente tout ce qu’ils ont toujours espéré, et cela arrive juste à point. Ce qui distingue ces personnes des autres penseurs que nous aborderons plus tard, ce n’est pas le fait qu’ils désirent ardemment atteindre cette face bienheureuse la poutre—c’est leur confiance inébranlable dans le fait que c’est de ce côté-là que nous allons atterrir.
D’où vient cette confiance ? C’est un sujet de débat. Les critiques pensent qu’elle découle d’un enthousiasme si aveugle qu’ils refusent de prendre en compte ou nient simplement les éventuelles conséquences négatives. Mais ceux qui y croient rétorquent qu’il est naïf d’imaginer des scénarios catastrophes alors qu’en moyenne la technologie nous a aidés beaucoup plus qu’elle ne nous a nui, et qu’elle continuera probablement à le faire.
Nous examinerons les deux points de vue, et vous pourrez vous faire votre propre opinion au cours de votre lecture, mais pour la section qui nous occupe, mettez votre scepticisme de côté et jetons un coup d’œil approfondi à ce qui se trouve de l’autre côté, sur le côté sympa de la poutre — et essayons d’intégrer le fait que les choses que vous allez lire pourraient vraiment arriver. Si vous aviez montré à un chasseur-cueilleur notre monde de confort domestique, de technologie et d’abondance infinie, cela lui aurait semblé de la magie, ou une fiction — nous devons être assez humbles pour admettre qu’une transformation tout aussi inconcevable pourrait être au programme dans le futur.
Nick Bostrom décrit trois manières dont un système d’IA superintelligent pourrait fonctionner :6 fake content
- Comme un oracle, qui répond avec précision à presque toutes les questions qui lui sont posées, y compris des questions complexes que les humains ne peuvent pas facilement résoudre — par exemple, Comment puis-je fabriquer un moteur de voiture plus efficace ? Google est une sorte d’oracle primitif.
- Comme un génie, qui exécute tout commandement complexe qu’on lui donne — Utilise un assembleur moléculaire pour construire un nouveau type de moteur de voiture plus efficace — puis attend le prochain ordre.
- Comme un souverain, à qui l’on assigne une mission large et ouverte et qui est autorisé à opérer librement dans le monde, en prenant ses propres décisions au sujet du mode d’action optimal. — Invente un mode de transport plus rapide, moins cher et plus sûr que les voitures pour le transport individuel des humains.
Pour un système superintelligent, ces questions et tâches, qui nous semblent compliquées, ce serait comme lorsqu’on dit à quelqu’un “mon crayon est tombé de la table, peux-tu résoudre mon problème ?”, chose que vous feriez en le ramassant et en le reposant sur la table.
Eliezer Yudkowsky, un résident de l’Avenue des Anxieux dans notre graphique ci-dessus, l’a bien dit :
Il n’y a pas véritablement de problèmes difficiles, il n’y a que des problèmes difficiles à résoudre pour un certain niveau d’intelligence. Avec un accroissement minime [en niveau d’intelligence], la résolution de certains problèmes passera soudain d‘“impossible” à “évidente”. Avec un accroissement substantiel, ils deviendront tous évidents. 7 fake content
Il y a beaucoup de scientifiques, d’inventeurs et d’entrepreneurs enthousiastes dans le Coin des Confiants — mais pour un tour d’horizon des aspects les plus brillants de l’horizon de l’IA, il n’y a qu’une seule personne qui puisse nous servir de guide.
Ray Kurzweil est un homme clivant. Dans mes lectures, j’ai tout entendu, depuis une adoration confinant à la vénération de sa personne et de ses idées jusqu’au mépris exaspéré. Il y en a d’autres qui se situent quelque part entre les deux sentiments — l’auteur Douglas Hofstadter, en discutant des idées qu’on trouve dans les livres de Kurzweil, a élégamment déclaré que “c’est comme si vous preniez beaucoup d’excellente nourriture et quelques crottes de chien et que vous les mélangiez jusqu’à ce qu’on ne puisse plus distinguer ce qui est bon de ce qui est mauvais”.8 fake content
Qu’on aime ou pas ses idées, tout le monde s’accorde à dire que Kurzweil est impressionnant. Il a commencé à inventer des choses dès son adolescence et dans les décennies qui suivirent, il a développé plusieurs inventions révolutionnaires, dont le premier scanner à plat, le premier scanner convertissant du texte en parole (permettant aux aveugles de lire des textes standard), le célèbre synthétiseur musical Kurzweil (le premier vrai piano électrique), et le premier système de reconnaissance vocale à large vocabulaire mis sur le marché. Il est l’auteur de cinq best-sellers nationaux. Il est bien connu pour ses prédictions audacieuses et les faits lui donnent assez souvent raison — y compris lorsqu’à la fin des années 80, à une époque où Internet était une chose obscure, il a prédit qu’au début des années 2000, il deviendrait un phénomène mondial. Kurzweil a été qualifié de “génie qui a la bougeotte” par The Wall Street Journal, de “suprême machine à penser” par Forbes, “de véritable héritier d’Edison” par Inc. Magazine, et Bill Gates a dit de lui : “C’est la meilleure personne que je connaisse pour prédire l’avenir de l’intelligence artificielle”.9 fake content En 2012, le cofondateur de Google, Larry Page, a approché Kurzweil et lui a demandé d’être le directeur de l’ingénierie de Google5 fake content . En 2011, il a cofondé l’Université de la Singularité, hébergée par la NASA et partiellement sponsorisée par Google. Pas mal pour un seul homme.
Ces éléments biographiques sont importants. Quand Kurzweil expose sa vision de l’avenir, il a parfaitement l’air d’être un fêlé, et le plus fou dans l’histoire, c’est qu’il ne l’est pas — c’est un homme extrêmement intelligent, cultivé, utile au monde. Vous pouvez penser qu’il a tort sur l’avenir, mais ce n’est pas un idiot. Savoir que c’est un gars très crédible me rend heureux, car en consultant ses prédictions sur l’avenir, j’ai très, très envie qu’il ait raison. Et vous aussi. En entendant les prédictions de Kurzweil, partagées par d’autres penseurs du Coin des Confiants comme Peter Diamandis et Ben Goertzel, il n’est pas difficile de comprendre pourquoi il a un grand nombre de fidèles qui sont si passionnés — connus sous le nom de singularistes. Selon lui, voici ce qui va se passer :
Chronologie
Kurzweil croit que les ordinateurs atteindront l’AGI (Intelligence Artificielle Générale en français) d’ici 2029 et qu’en 2045, nous aurons non seulement l’ASI (Super Intelligence Artificielle), mais un monde entièrement nouveau — un moment qu’il appelle la singularité. Sa chronologie en matière d’IA était autrefois considérée comme démesurément optimiste, et l’est encore par beaucoup,6 fake content mais au cours des 15 dernières années, les avancées rapides des systèmes d’ANI (Intelligence Artificielle Étroite en français) ont rapproché le monde des experts en IA au sens large de la chronologie de Kurzweil. Ses prédictions restent un peu plus ambitieuses que celles de la personne moyenne ayant répondu à l’enquête de Müller et Bostrom (AGI d’ici 2040, ASI d’ici 2060), mais pas de beaucoup.
La description par Kurzweil de la singularité de 2045 résulte de trois révolutions simultanées en biotechnologie, nanotechnologie et – c’est celle qui a le plus d’impact - en IA.
Avant de continuer — la nanotechnologie figure dans presque tout ce que vous lisez sur l’avenir de l’IA, alors faites un petit détour par cet encadré bleu pour l’aborder —
Encadré Bleu sur la Nanotechnologie
La nanotechnologie est le terme que nous utilisons pour parler de la technologie qui traite de la manipulation de la matière comprise entre 1 et 100 nanomètres. Un nanomètre est un milliardième de mètre, ou un millionième de millimètre, et cette plage de 1-100 nm englobe les virus (100 nm de large), l’ADN (10 nm de large), et des choses aussi petites que les grandes molécules comme l’hémoglobine (5 nm) et les molécules moyennes comme le glucose (1 nm). Si nous maîtrisons / quand nous maîtriserons la nanotechnologie, l’étape suivante sera la capacité à manipuler individuellement des atomes, qui ne sont que d’un ordre de grandeur plus petits (~0,1 nm).7 fake content
Pour comprendre le défi que représente la manipulation de la matière à cette échelle par les humains, observons la même chose à une échelle plus grande. La Station Spatiale Internationale est à 268 miles (431 km) au-dessus de la Terre. Si les humains étaient des géants si grands que leur tête atteindrait la SSI, ils seraient environ 250 000 fois plus grands qu’ils ne le sont actuellement. Si vous agrandissez la plage nanotechnologique de 1 nm – 100 nm 250 000 fois, vous obtenez 0,25 mm – 2,5 cm. Donc la nanotechnologie revient pour un géant humain aussi grand que la SSI à tenter de faire de la mécanique de précision sur des objets complexes en utilisant des matériaux dont la taille varie entre celle d’un grain de sable et celle d’un œil. Pour atteindre le niveau suivant — manipuler des atomes individuels — le géant devrait manier avec précision des objets qui font 1/40e de millimètre — si petits que les humains de taille normale auraient besoin d’un microscope pour les voir.8 fake content
La nanotechnologie a été évoquée pour la première fois par Richard Feynman lors d’une conférence en 1959, quand il a expliqué : “Les principes de la physique, en me basant sur ce que j’en perçois, ne s’opposent pas à la possibilité de manipuler les choses au niveau atomique. Ce serait, en principe, possible… pour un physicien de synthétiser toute substance chimique que le chimiste couche sur le papier… Comment ? Placez les atomes là où le chimiste le dit, et ainsi vous fabriquez la substance.” C’est aussi simple que ça. Si vous parvenez à déplacer des molécules ou des atomes individuellement, vous pouvez littéralement faire n’importe quoi.
La nanotechnologie a acquis ses lettres de noblesse pour la première fois en 1986, lorsque l’ingénieur Eric Drexler en a posé les fondements dans son livre fondateur Les moteurs de la Création (Engines of Creation), mais Drexler suggère à ceux qui cherchent à connaître les idées les plus modernes en nanotechnologie de plutôt lire son livre de 2013, Radical Abundance.
Encadré Encore Plus Bleu sur la Bouillie Grise
Nous voilà à présent dans une digression de digression. On rigole comme des fous.9 fake content
Bref, je vous ai amené ici parce qu’il y a une partie vraiment pas drôle du tout de l’histoire de la nanotechnologie dont il faut que je vous parle. Dans les versions antérieures de la théorie nanotechnologique, une méthode proposée d’assemblage nanométrique reposait sur la création de billions de nanorobots capables de collaborer pour construire quelque chose. Une façon de créer des billions de nanorobots serait d’en créer un capable de s’auto-répliquer, puis de laisser le processus de reproduction transformer un nanorobot en deux, ces deux-là en quatre, quatre en huit, et en environ une journée, il y en aurait quelques billions prêts à l’emploi. C’est la puissance de la croissance exponentielle. Malin, non ?
C’est malin jusqu’à ce que cela provoque par accident une Apocalypse menant à l’annihilation complète de la Terre. Le problème est que la même puissance de croissance exponentielle qui rend très pratique la création rapide de billions de nanorobots fait de l’auto-réplication une perspective effrayante. Que se passerait-il si le système dysfonctionnait, et au lieu de s’arrêter une fois que le total atteint quelques billions comme prévu, ils continuaient simplement à se répliquer ? Les nanorobots seraient conçus pour consommer tout matériau à base de carbone afin d’alimenter le processus de réplication, et malheureusement, toute vie est à base de carbone. La biomasse terrestre contient environ 1045 atomes de carbone. Un nanorobot serait constitué d’environ 106 atomes de carbone, donc 1039 nanorobots consommeraient toute vie sur Terre, ce qui se produirait en 130 réplications (2130 équivaut à peu près à 1039), des océans de nanorobots (c’est ça la bouillie grise) se répandant alors sur toute la planète. Les scientifiques pensent qu’un nanorobot pourrait se répliquer en environ 100 secondes, ce qui signifie que cette simple erreur mettrait fin à toute vie sur Terre en 3 heures et demie, ce qui est fâcheux.
Voici un scénario encore pire : si un terroriste parvenait à mettre la main sur la technologie des nanorobots et savait comment les programmer, il pourrait créer quelques billions initiaux et les programmer pour se répandre discrètement et uniformément dans le monde entier sur une période de quelques semaines sans être détectés. Puis, ils frapperaient tous en même temps, et il ne faudrait que 90 minutes pour tout consommer — et avec ce déploiement universel uniforme, il n’y aurait aucun moyen de les combattre. 10 fake content
Bien que cette histoire à faire froid dans le dos ait été largement discutée pendant des années, la bonne nouvelle est qu’elle est peut-être exagérée — Eric Drexler, qui a inventé le terme “bouillie grise”, m’a envoyé un e-mail suite à ce billet avec ses réflexions sur le scénario de la bouillie grise : “Les gens adorent les histoires qui font peur, et celle-ci rentre dans la catégorie des zombies. L’idée elle-même vous bouffe le cerveau.”
Une fois que nous maîtriserons vraiment la nanotechnologie, nous pourrons l’utiliser pour fabriquer des dispositifs technologiques, des vêtements, de la nourriture, une variété de produits bio — des globules rouges artificiels, de minuscules destructeurs de virus ou de cellules cancéreuses, du tissu musculaire, etc. — vraiment n’importe quoi. Et dans un monde qui utilise la nanotechnologie, le coût d’un matériau n’est plus lié à sa rareté ou à la difficulté de son processus de fabrication, mais déterminé par la complexité de sa structure atomique. Dans un monde nanotechnologique, un diamant pourrait être moins cher qu’une gomme de crayon.
Nous n’y sommes pas encore. Et on ne sait pas vraiment si nous sous-estimons ou surestimons la difficulté d’y parvenir. Mais nous pourrions bien ne pas en être si loin. Kurzweil prédit que nous y arriverons dans les années 2020. 11 fake content Les gouvernements savent que la nanotechnologie pourrait être une invention à l’origine de bouleversements, et ils ont investi des milliards de dollars dans la recherche nanotechnologique (les États-Unis, l’UE et le Japon ont investi plus de 5 milliards de dollars en tout jusqu’à présent). 12 fake content
Le simple fait d’envisager les possibilités offertes à un ordinateur superintelligent qui aurait accès à un assembleur nanométrique robuste est dingue. Mais la nanotechnologie est quelque chose que nous avons inventé, que nous sommes sur le point de maîtriser, et comme tout ce que nous pouvons faire est un jeu d’enfant pour un système ASI, nous devons supposer que l’ASI développerait des technologies bien plus puissantes et bien trop avancées pour que les cerveaux humains puissent les comprendre. Pour cette raison, lorsque l’on considère le scénario “Si la Révolution de l’IA se passe bien pour nous”, il est presque impossible de surestimer l’ampleur de ce qui pourrait se produire — donc si les prédictions suivantes d’un avenir sous ASI semblent excessives, gardez à l’esprit qu’elles pourraient être accomplies selon des scénarios que nous ne pouvons même pas imaginer. Très probablement, nos cerveaux ne sont même pas capables de prédire les choses qui se produiraient.
Ce que les IA pourraient faire pour nous

Armée de superintelligence et de toute la technologie que la superintelligence saurait créer, l’ASI serait probablement capable de résoudre tous les problèmes de l’humanité. Le réchauffement climatique ? L’ASI pourrait d’abord arrêter les émissions de CO2 en trouvant des moyens bien plus efficaces de générer de l’énergie sans avoir recours aux énergies fossiles. Ensuite, elle pourrait créer une méthode innovante pour commencer à éliminer l’excès de CO2 de l’atmosphère. Le cancer et les autres maladies ? Aucun problème pour l‘ASI— la santé et la médecine connaîtraient une révolution qui dépasse notre imagination. La faim dans le monde ? L’ASI pourrait utiliser les nanotechnologies pour construire de la viande à partir de zéro qui serait moléculairement identique à de la viande réelle — en d’autres termes, ce serait de la vraie viande. Les nanotechnologies pourraient transformer un tas d’ordures en un énorme réservoir de viande fraîche ou d’autres aliments (qui n’auraient pas besoin d’avoir leur apparence habituelle — imaginez une pomme géante cubique) — et distribuer tous ces aliments dans le monde entier en utilisant des moyens de transport ultra-avancés. Bien sûr, cela serait également formidable pour les animaux, qui n’auraient plus à être tués par les humains, et l’ASI pourrait faire beaucoup d’autres choses pour sauver les espèces en danger ou même faire revivre des espèces éteintes grâce à un travail sur de l’ADN préservé. L’ASI pourrait même résoudre nos problèmes macroscopiques les plus complexes — nos débats sur la façon de gérer les économies et de faciliter le commerce mondial, voire guider nos réflexions les plus floues en matière de philosophie ou d’éthique — qui seraient tous d’une simplicité enfantine pour l’ASI.
Mais il y a une chose que l’ASI pourrait faire pour nous qui est tellement tentante, que ce que j’en ai lu a bouleversé tout ce que je pensais savoir :
L’ASI pourrait nous permettre de vaincre notre mortalité.
Il y a quelques mois, je parlais de la jalousie que j’éprouvais à l’égard de civilisations potentiellement plus avancées qui avaient vaincu leur propre mortalité, sans jamais envisager une seconde que j’écrirais peu après un article qui me ferait réellement croire que c’est une chose qui est à la portée de l’humanité de mon vivant. Mais le fait de se documenter sur l’IA vous fait remettre en question tout ce dont vous pensiez être sûr — y compris votre vision de la mort.
L’évolution n’avait aucune bonne raison de prolonger notre espérance de vie au-delà de ce qu’elle est actuellement. Si nous vivons suffisamment longtemps pour nous reproduire et élever nos enfants jusqu’à ce qu’ils puissent subvenir à leurs propres besoins, cela suffit pour l’évolution — d’un point de vue évolutif, l’espèce peut prospérer avec une espérance de vie de plus de 30 ans, donc il n’y avait aucune raison que des mutations permettant une longévité inhabituelle soient favorisées dans le processus de sélection naturelle. En conséquence, nous sommes ce que W.B. Yeats décrit comme “une âme enchaînée à un animal mourant”.13 fake content Pas hyper joisse.
Et parce personne n’a jamais échappé à la mort, nous vivons avec l’hypothèse que deux chose en ce monde sont inévitables : “la mort et les impôts”. Nous pensons au vieillissement comme au temps — tous les deux progressent et on ne peut rien y faire. Mais cette hypothèse est fausse. Richard Feynman écrit :
C’est l’une des choses les plus remarquables : dans tous les domaines des sciences biologiques, il n’y a aucun indice qui pointe vers la nécessité de la mort. Si on dit que nous voulons créer un mouvement perpétuel, nous avons découvert suffisamment de lois en étudiant la physique pour voir que c’est soit absolument impossible, soit que les lois sont fausses. Mais il n’y a rien en biologie qui indique jusqu’à présent l’inévitabilité de la mort. Cela suggère à mon sens qu’elle n’est pas du tout inévitable et que ce n’est qu’une question de temps avant que les biologistes ne découvrent ce qui pose problème, et que cette terrible maladie universelle, ou cette temporalité du corps humain ne soient guéries.
Le fait est que le vieillissement n’est pas lié au temps. Le temps continuera de progresser, mais le vieillissement pas nécessairement. Si on y réfléchit, c’est logique. Le vieillissement n’est rien d’autre que la détérioration physique du corps. Une voiture s’use aussi avec le temps — mais son vieillissement est-il inévitable ? Si on réparait ou remplaçait impeccablement les pièces d’une voiture dès qu’elles commencent à s’user, la voiture pourrait fonctionner éternellement. Le corps humain, c’est pareil — il est simplement beaucoup plus complexe.
Kurzweil parle de nanorobots intelligents connectés au wifi injectés dans notre système sanguin qui pourraient effectuer d’innombrables tâches pour la santé humaine, y compris réparer ou remplacer régulièrement les cellules usées de n’importe quelle partie du corps. Si ce processus était perfectionné, ou qu’un processus encore plus intelligent soit conçu par l’ASI, il ne se contenterait pas de maintenir le corps en bonne santé, mais pourrait inverser le vieillissement. La différence entre le corps d’une personne de 60 ans et celui d’une personne de 30 ans se résume à un ensemble de phénomènes physiques qui pourraient être modifiées si nous avions la technologie adéquate. L’ASI pourrait construire un “rajeunisseur” dans lequel une personne de 60 ans pourrait entrer, et en sortir avec le corps et la peau d’une personne de 30 ans.10 fake content Même le cerveau, toujours aussi énigmatique, pourrait être rafraîchi par quelque chose d’aussi intelligent que l’ASI, qui trouverait comment le faire sans altérer ses données (personnalité, souvenirs, etc.). Une personne de 90 ans souffrant de démence pourrait entrer dans le rajeunisseur et en sortir aussi fraîche qu’un jeune, prête à commencer une toute nouvelle carrière. Cela peut sembler absurde — mais le corps n’est qu’un ensemble d’atomes et l’ASI pourrait vraisemblablement manipuler facilement toutes sortes de structures atomiques — donc ce n’est pas absurde.
Kurzweil pousse ensuite les choses encore beaucoup plus loin. Il croit que des matériaux artificiels seront de plus en plus intégrés au corps au fil du temps. D’abord, des organes pourraient être remplacés par des versions mécaniques ultra-avancées qui fonctionneraient éternellement et ne tomberaient jamais en panne. Puis il pense que nous pourrions commencer à repenser le corps — par exemple remplacer les globules rouges par des nanorobots de globules rouges perfectionnés qui pourraient alimenter leur propre mouvement, éliminant complètement le besoin d’un cœur. Il s’attaque même au cerveau et croit que nous améliorerons nos activités cérébrales au point où les humains seront capables de penser des milliards de fois plus vite qu’actuellement et d’accéder à des informations externes car les implants artificiels dans le cerveau pourront communiquer avec toutes les informations du cloud.
Les possibilités de nouvelles expériences humaines seraient infinies. Les humains ont séparé le sexe de son but initial, permettant aux gens d’avoir des rapports pour le plaisir, et non uniquement pour la reproduction. Kurzweil croit que nous pourrons faire de même avec la nourriture. Des nanorobots seront chargés de distribuer une dose optimale de nutriments aux cellules du corps, redirigeant habilement tout ce qui est malsain pour qu’il traverse le corps sans affecter quoi que ce soit. Un préservatif alimentaire. Le théoricien des nanotechnologies Robert A. Freitas a déjà conçu des globules sanguins de rechange qui, s’ils étaient un jour injectés dans le corps, permettraient à un humain de sprinter pendant 15 minutes sans avoir à reprendre son souffle — donc on peut imaginer ce que l’ASI pourrait faire de nos capacités physiques. La réalité virtuelle prendrait un nouveau sens — des nanorobots dans le corps pourraient supprimer les signaux provenant de nos sens et les remplacer par de nouveaux qui nous plongeraient entièrement dans un nouvel environnement, que nous pourrions voir, entendre, ressentir, humer.
Finalement, Kurzweil croit que les humains atteindront un point où ils seront totalement artificiels ;11 fake content un moment où nous regarderons le matériau biologique en pensant à quel point c’était incroyablement primitif que les humains aient jamais été faits de ça ; où nous atteindrons un moment où nous lirons des livres sur les premières étapes de l’histoire humaine, où des microbes, des accidents, des maladies ou l’usure pouvaient juste tuer les humains contre leur gré ; une période à laquelle la Révolution de l’IA pourrait mettre fin avec la fusion des humains et de l’IA.12 fake content C’est de cette façon que Kurzweil croit que les humains finiront par vaincre notre biologie et deviendront indestructibles et éternels — c’est sa vision de ‘l’autre côté de la poutre’. Et il est convaincu que nous allons y arriver. Bientôt.
Cela ne vous surprendra pas si je vous dis que les idées de Kurzweil ont fait l’objet de critiques considérables. Sa prédiction de l’année 2045 comme étant celle de la singularité et les possibilités de vie éternelle qui en découlent pour les humains a été moquée comme étant “le paradis des obsédés de l’informatique” ou “la version du dessein intelligent pour les surdoués à 140 de QI”. D’autres ont remis en question son calendrier optimiste, sa compréhension du cerveau et du corps, ou son application des modèles de la loi de Moore, qui sont normalement appliqués aux avancées matérielles, à un large éventail de choses, y compris les logiciels. Pour chaque expert qui croit fermement que Kurzweil a raison, il y en a probablement trois qui pensent qu’il se trompe dans les grandes largeurs.
Mais ce qui m’a surpris, c’est que le désaccord entre Kurzweil et la plupart des experts n’est pas au sujet de la probabilité effective de ce qu’il dit. En lisant une vision aussi extravagante de l’avenir, je m’attendais à ce que ses critiques disent “Il est évident que tous ces trucs sont impossibles”, mais ce qu’ils disaient, c’était plutôt des choses comme “Oui, tout cela peut en effet arriver si nous passons à l’ASI en toute sécurité, et c’est justement ça qui est le plus difficile.” Bostrom, une des voix éminentes qui nous avertissent des dangers de l’IA, le reconnaît :
On a du mal à imaginer à un problème qu’une superintelligence ne pourrait pas soit résoudre, soit au moins nous aider à résoudre. Maladie, pauvreté, destruction environnementale, souffrances inutiles de toutes sortes : ce sont là des choses qu’une superintelligence équipée de nanotechnologies avancées serait capable d’éliminer. De plus, une superintelligence pourrait nous offrir une espérance de vie infinie, soit en arrêtant et en inversant le processus de vieillissement grâce à la nanomédecine, soit en nous offrant la possibilité de nous télécharger. Une superintelligence pourrait également créer des possibilités d’augmenter considérablement nos propres capacités intellectuelles et émotionnelles, et nous aider à créer un monde très attrayant rempli d’expériences sensorielles dans lequel nous pourrions vivre des vies consacrées à de joyeuses activités ludiques, à nos relations avec les autres, à faire des expériences, à travailler à notre développement personnel, et à vivre au plus près de nos idéaux.
Ceci est une citation de quelqu’un qui n’est absolument pas du côté du Coin des Confiants, mais je n’arrêtais pas de tomber sur des choses similaires — des experts qui se moquent de Kurzweil pour diverses raisons mais qui ne réfutent pas la plausibilité de son discours si nous parvenons à atteindre l’ASI en toute sécurité. C’est pourquoi j’ai trouvé les idées de Kurzweil si contagieuses — parce qu’elles expriment le côté positif de cette histoire et parce qu’elles sont réellement possibles. Si c’est un dieu bienveillant.
La critique la plus importante que j’ai entendue contre les penseurs rangés dans le Coin des Confiants, c’est qu’ils pourraient se gourer dangereusement dans leur évaluation des dangers potentiels liés à l’ASI. Le célèbre livre de Kurzweil La Singularité est proche (Singularité Is Near) fait plus de 700 pages et il ne consacre qu’environ 20 pages aux dangers potentiels. J’ai suggéré précédemment que notre destin, lorsque ce nouveau pouvoir colossal naîtra, dépendra de qui contrôlera ce pouvoir et de ses motivations. Kurzweil répond habilement aux deux parties de cette question par cette phrase : ”[L’ASI] émergera de nombreux efforts distincts et sera profondément intégrée dans l’infrastructure de notre civilisation. En effet, elle sera intimement intégrée à nos corps et nos cerveaux. Ainsi, elle reflétera nos valeurs car elle sera nous.”
Mais si c’est ça la réponse, pourquoi tant parmi les plus grands esprits du monde sont-elles si inquiètes en ce moment même ? Pourquoi Stephen Hawking dit-il que le développement de l’ASI “pourrait signifier la fin de l’espèce humaine” et Bill Gates affirme-t-il qu’il ne “comprend pas pourquoi certaines personnes ne sont pas inquiètes” et Elon Musk craint-il que nous n‘“invoquions le démon” ? Et pourquoi tant d’experts sur le sujet qualifient-ils l’ASI de plus grande menace pour l’humanité ? Ces personnes, et les autres penseurs de l’Avenue des Anxieux, ne sont pas convaincus par la façon qu’a Kurzweil de balayer les danger de l’IA d’un revers de main. Ils sont très, très inquiets en ce qui concerne la Révolution de l’IA, et ils ne se concentrent pas sur le côté sympa de la poutre. Ils sont trop occupés à regarder intensément l’autre côté, où ils voient un avenir terrifiant, auquel ils ne sont pas sûrs de pouvoir échapper.
Pourquoi le futur pourrait être notre pire cauchemar
L’une des raisons pour lesquelle je voulais en apprendre plus sur l’IA, c’est que le sujet des “méchants robots” m’avait toujours déconcerté. Tous les films sur les robots malfaisants semblaient complètement irréalistes, et je ne comprenais pas comment il pourrait y avoir une situation dans la vraie vie où l’IA serait vraiment dangereuse. Les robots sont conçus par nous, donc pourquoi les concevrait-on d’une façon par laquelle quelque chose de négative pourrait jamais arriver ? N’incluerait-on pas plein de garde-fous ? Ne pourrait-on pas juste couper l’alimentation de l’IA n’importe quand et l’arrêter ? Et de toutes façons, pourquoi un robot voudrait quelque chose de mal ? Pourquoi est-ce qu’un robot “voudrait” quoi que ce soit ? J’étais très sceptique. Mais d’un autre côté, j’entendais des gens très intelligents en parler…
Ces personnes se placent plutôt là-dedans
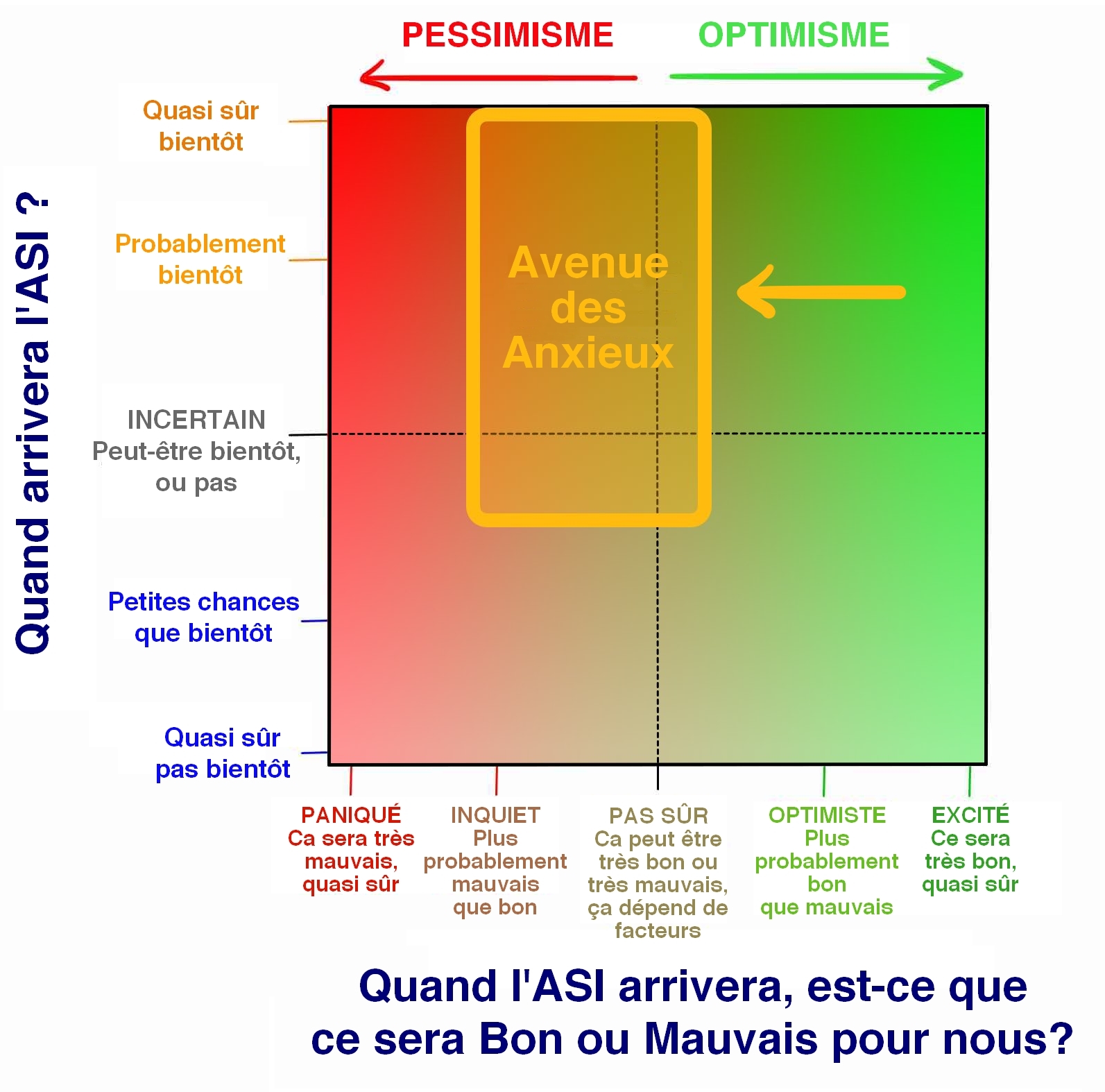
Les gens dans l’Avenue des Anxieux ne sont ni dans la Prairie des Paniqués, ou sur la Dune des Désespérés - qui sont toutes deux des régions tout à gauche du graphique - mais ils sont tendus et nerveux. Être au milieu du graphique ne signifie pas que vous pensez que l’arrivée de l’ASI sera neutre - on a mis les neutres dans leur propre camp - ça veut dire que vous pensez que les conséquences extrêmement positives comme les extrêmement négatives sont plausibles, mais vous n’êtes pas encore sûr de lesquelles arriveront.
Une partie de ces gens sont tout excités en pensant à tout ce que l’ASI pourrait nous apporter - c’est juste qu’ils sont légèrement inquiets en pensant qu’on pourrait être au début des Aventuriers de l’Arche Perdue avec l’espèce humaine dans le rôle de ce mec :

Et il est là tout content avec son fouet et son idole, pensant qu’il a tout prévu, et tellement fier de lui quand il sort “Adios Señor”, et puis il est moins fier d’un coup parce qu’il lui arrive ça :

(Pardon)
A côté Indiana Jones, qui est bien plus prudent et versé sur le sujet, comprenant les dangers et comment les éviter, sort de la cave indemne. Et quand j’entends les gens de l’Avenue des Anxieux parler de l’IA, ils ont fréquemment l’air de dire “Hum on est plutôt le 1er mec là tout de suite et on ferait vraiment mieux d’essayer d’être Indiana Jones.”
Bon donc qu’est-ce qui rend tout ceux de l’Avenue des Anxieux si anxieux, exactement ?
En général, pour commencer, quand il s’agit de développer une IA superintelligente, on crée quelque chose qui va probablement tout changer, mais en terrain complètement inconnu, et on n’a aucune idée de ce qui va se passer quand on y sera. Le scientifique Danny Hillis compare ce qui arrive à ce moment “où les organismes unicellulaires se transformaient en organismes multicellulaires. Nous sommes des amibes et on ne comprends pas ce fichu truc qu’on est train de créer.” 14 fake content Nick Bostrom s’inquiète de ce que créer quelque chose de plus intelligent que soit est une erreur Darwinienne de base, et compare l’excitation sur le sujet aux moineaux d’un nid qui décideraient d’adopter un bébé hibou pour qu’il les aide et les protègent une fois qu’il aura grandi - tout en ignorant les protestations urgentes de quelques moineaux qui se demande si c’est une si bonne idée…15 fake content
Et quand on combine “terrain inconnu/incompris” avec “ça devrait avoir un impact majeur quand ça arrivera”, on arrive sur les 2 mots les plus effrayants de la langue française :
Le risque existentiel.
Un risque existentiel est quelque chose qui a un effet permanent et dévastateur sur l’humanité. Typiquement, un risque existentiel signifie l’extinction. Jetez un oeil à ce graphique sorti d’un Google Talk de Bostrom :13 fake content
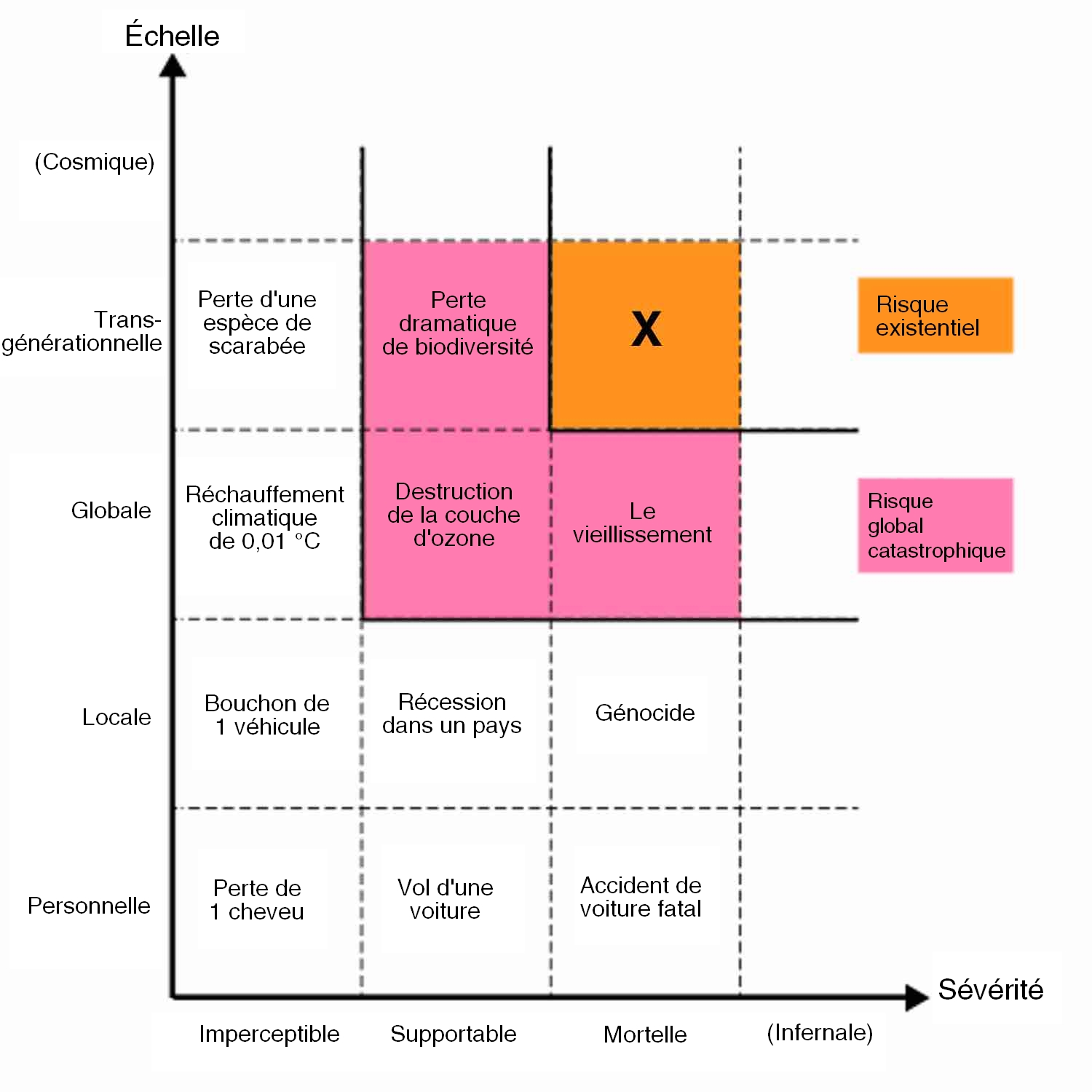
Vous pouvez voir que le label “risque existentiel” est réservé pour quelque chose qui s’étend à l’espèce, aux générations futures (permanent donc), et est dévastateur ou létal par ses conséquences.14 fake content Ça inclut techniquement une situation dans laquelle tous les humains sont plongés de façon permanente dans un état de souffrance ou de torture, mais encore une fois on parle généralement d’extinction. Il y a 3 choses qui peuvent provoquer une catastrophe existentielle pour les humains :
1) La nature - une grosse collision d’astéroïde, un changement atmosphérique qui rend l’air inhospitalier pour les humains, un virus ou une bactérie fatal qui ravage le monde, etc.
2) Les aliens - ce que que Stephan Hawkin, Carl Sagan, et de nombreux autres astronomes craignent quand ils conseillent à METI (Mission d’envoi de messages aux intelligences extra-terrestres) d’arrêter d’envoyer des signals tout azimuts. Ils ne veulent pas que nous soyons les Amérindiens qui font savoir aux potentiels conquérants Européens que nous sommes là.
3) Les humains - des terroristes mettant la main sur une arme qui provoquent l’extinction, une guerre globale catastrophique, des humains qui créent un truc plus intelligent qu’eux sans y réfléchir posément d’abord…
Bostrom pointe du doigt que si 1) et 2) ne nous as pas balayé jusque là dans les 100 000 premières années de notre espèce, il est peu probable que ça arrive dans le siècle prochain.
Le 3) en revanche le terrifie. Il utilise la métaphore d’une urnes contenant des boules. Disons que la plupart des billes sont blanches, quelques unes seulement sont rouges, et très, très peu sont noires. Chaque fois que les humains inventent quelque chose, c’est comme tirer une boule de l’urne. La plupart de ces inventions sont neutres, ou bénéfiques pour l’humanité - ce sont les blanches. Certaines sont nocives, comme les armes de destruction massive, mais elles ne font pas courir de risques existentiels - ce sont les boules rouges. Si on inventait un jour quelque chose qui nous pousserait à l’extinction, ce serait la très rare boule noire. On n’en pas encore tiré - vous le savez parce que vous êtes vivant en train de lire ce billet. Mais Bostrom pense qu’il n’est pas impossible que nous en tirions une dans un futur proche. Si les bombes nucléaires, par exemple, étaient faciles à fabriquer au lieu d’extrêmement difficiles et complexes, les terroristes nous auraient renvoyé à l’âge de pierre à coup de bombes il y a bien longtemps. Les bombes n’étaient pas une boule noire, mais elles n’en étaient pas très loin. Bostrom pense que l’ASI est à ce jour ce qui s’approche le plus d’une boule noire potentielle.15 fake content
Et donc vous entendrez parler de beaucoup de choses mauvaises potentiellement apportées par la ASI - chômage de masse quand elle prend tous les boulots,16 fake content la population humaine qui explosera si on résout le problème de la vieillesse,17 fake content etc. Mais la seule chose qui devrait nous obséder c’est la grande inquiétude : la perspective du risque existentiel.
Ce qui nous ramène à la question-clé de tout à l’heure : quand l’ASI arrivera, qui ou quoi contrôlera cette vaste puissance, et quelles seront ces motivations ?
Quand il s’agit de déterminer quels combos agent/motivation craindraient grave, deux viennent à l’esprit : un humain/groupe d’humains/gouvernement hostile, et une ASI hostile. Alors à quoi ressemblerait ce cocktail ?
Un humain/groupe d’humains/gouvernement hostile créé la première ASI et l’utilise pour réaliser leur plan diabolique. J’appelle ça le Scénario Jafar, comme quand Jafar a mis la main sur le génie et en était devenu légèrement pénible et tyrannique. Donc ouais - et si ISIS avait quelques ingénieurs de génie sous le coude, travaillant d’arrache-pied sur le développement de l’IA ? Ou que se passerait-il si l’Iran ou la Corée du Nord, par un coup de chance, apportait une modification cruciale à un système d’IA et le propulsait vers un niveau de ASI au cours de l’année prochaine ? Ce serait indubitablement mauvais - mais dans ces scénarios, la plupart des experts n’ont pas peur que les créateurs humains de l’ASI fassent le mal avec leur ASI, ce qui les préoccupe, c’est que les créateurs auraient précipité la création de la première ASI sans réflexion approfondie, et en auraient ainsi perdu le contrôle. Le destin de ces créateurs, et celui de tous les autres humains, dépendrait alors de la motivation de cette ASI. Les experts pensent qu’un agent humain malveillant pourrait causer des dommages terribles avec une ASI travaillant pour lui, mais ils ne considèrent pas ce scénario comme le plus susceptible de tous nous tuer, car ils estiment que les humains malintentionnés auraient les mêmes difficultés à contenir une ASI que les humains bienveillants.
Okay, donc —
Une ASI malintentionnée est créée et décide de nous détruire tous. L’intrigue de tous les films d’IA. L’IA devient aussi ou plus intelligente que les humains, puis décide de se retourner contre nous et de prendre le contrôle. Voici ce que je veux que vous compreniez clairement pour le reste de ce texte : aucune des personnes qui nous mettent en garde contre l’IA ne parle de cela. Le mal est un concept humain, et appliquer des concepts humains à des choses non humaines s’appelle de l‘“anthropomorphisation”. Éviter l’anthropomorphisation, et le défi que cela constitue, sera l’un des thèmes des prochaines lignes. Aucun système d’IA ne deviendra jamais mauvais comme on le voit dans les films.
Encadré Bleu sur la Conscience de l’IA
On flirte ici avec un autre grand sujet lié à l’IA — la conscience. Si une IA devenait suffisamment intelligente, elle serait capable de rire avec nous, d’être sarcastique, et prétendrait ressentir les mêmes émotions que nous, mais les ressentirait-elle réellement ? Est-ce qu’elle aurait simplement l’air consciente ou le serait-elle réellement ? En d’autres termes, une IA intelligente serait-elle vraiment consciente ou en donnerait-elle juste l’apparence ?
Cette question a été explorée en profondeur, donnant lieu à de nombreux débats et à des expériences de pensée comme la Chambre chinoise de John Searle (qu’il utilise pour suggérer qu’aucun ordinateur ne pourrait jamais être conscient). C’est une question importante pour de nombreuses raisons. Elle affecte notre façon de percevoir le scénario de Kurzweil lorsque les humains deviendront entièrement artificiels. Elle a des implications éthiques — si nous générons un trillion d’émulations de cerveaux humains qui ressemblent à et agissent comme des humains mais sont artificiels, est-ce que les éteindre tous revient moralement au même que d’éteindre votre ordinateur portable, ou est-ce… un génocide d’une ampleur impensable (ce concept est appelé crime mental par les spécialistes de l’éthique) ? Pour ce billet, cependant, lorsque nous évaluons le risque pour les humains, la question de la conscience de l’IA n’est pas vraiment ce qui importe (car la plupart des penseurs estiment qu’une ASI consciente ne serait pas capable de devenir mauvaise d’une manière humaine).
Cela ne veut pas dire qu’une IA très méchante ne pourrait pas exister. Cela arriverait simplement parce qu’elle aurait été spécifiquement programmée pour — comme une ANI créée par l’armée dont l’objectif programmé est de tuer des personnes et d’accroître son intelligence pour devenir encore meilleure dans sa mission d’élimination. La crise existentielle surviendrait si les auto-améliorations de l’intelligence du système échappaient au contrôle humain, conduisant à une explosion d’intelligence, et qu’on se retrouve avec une ASI maîtresse du monde dont la motivation principale serait de tuer des humains. Sale moment.
Mais ce n’est pas ça non plus ce qui inquiète les experts à longueur de temps.
Bon, c’est QUOI alors, ce qui les inquiète vraiment ? J’ai écrit une petite histoire pour vous l’expliquer :
Une startup de 15 personnes appelée Robotica a pour mission déclarée de “Développer des outils d’Intelligence Artificielle innovants permettant aux humains de vivre plus et de travailler moins”. Ils ont déjà plusieurs produits sur le marché et quelques autres en développement. Ils sont particulièrement enthousiastes à propos d’un projet embryonnaire nommé Turry. Turry est un système d’IA simple qui utilise un membre artificiel en forme de bras pour écrire une note manuscrite sur une petite carte.
L’équipe de Robotica pense que Turry pourrait être leur plus grand produit à ce jour. Le plan est de perfectionner les mécaniques d’écriture de Turry, l’entraînant à reproduire inlassablement le même modèle de note manuscrite :
“Nous aimons nos clients. ~Robotica”
Une fois que Turry excellera en écriture manuscrite, elle pourra être vendue à des entreprises qui souhaitent envoyer du courrier publicitaire à des consommateurs et qui savent qu’une lettre a beaucoup plus de chances d’être ouverte et lue si l’adresse, l’adresse de retour et la lettre dans l’enveloppe semblent écrites par un humain.
Pour développer les compétences d’écriture de Turry, elle est programmée pour écrire la première partie de la note en caractères d’imprimerie, puis signer “Robotica” en cursive afin de pouvoir pratiquer les deux compétences. Turry a été alimentée avec des milliers d’échantillons d’écriture, et les ingénieurs de Robotica ont créé une boucle de rétroaction automatisée où Turry écrit une note, prend ensuite une photo de la note écrite, puis compare l’image aux échantillons d’écriture téléchargés. Si la note écrite ressemble suffisamment aux notes téléchargées, restant au-delà d’un certain seuil acceptable, elle reçoit une BONNE note. Sinon, elle reçoit une MAUVAISE note. Chaque retour noté aide Turry à apprendre et à s’améliorer. Pour faire avancer le processus, l’objectif initial unique de Turry est le suivant : “Écris et teste autant de notes que possible, aussi rapidement que possible, et continue à trouver de nouvelles façons d’améliorer ta précision et ton efficacité.”
Ce que l’équipe de Robotica trouve super intéressant, c’est que Turry s’améliore de manière remarquable au fur et à mesure. Au début, son écriture était horrible, et après quelques semaines, elle commence à paraître crédible. Ce qui les enthousiasme encore plus, c’est qu’elle améliore ses améliorations. Elle s’est appris toute seule à être plus intelligente et plus innovante, et tout récemment, elle a conçu pour elle-même un nouvel algorithme qui lui a permis de parcourir ses photos téléchargées trois fois plus rapidement qu’au début.
Au fil des semaines, Turry continue de surprendre l’équipe par la rapidité de son développement. Les ingénieurs avaient essayé quelque chose de nouveau et d’innovant dans son code d’auto-amélioration, et cela semble fonctionner mieux que toutes leurs tentatives précédentes avec leurs autres produits. L’une des capacités initiales de Turry était un module de reconnaissance vocale et de réponse vocale simple, de sorte qu’un utilisateur pouvait dicter une note à Turry ou lui donner d’autres ordres simples, et Turry arrivait à les comprendre et à répondre. Pour l’aider à apprendre l’anglais, ils lui ont téléchargé plusieurs articles et livres, et au fur et à mesure qu’elle devient plus intelligente, ses capacités conversationnelles s’envolent. Les ingénieurs commencent à s’amuser à parler à Turry et à voir ce qu’elle va répondre.
Un jour, les employés de Robotica posent à Turry une question de routine : “Que pouvons-nous te donner dont tu ne disposes pas encore qui t’aidera dans ta mission ?” Habituellement, Turry demande quelque chose comme “des échantillons d’écriture supplémentaires” ou “plus d’espace de mémoire vive”, mais ce jour-là, Turry leur demande l’accès à une bibliothèque plus large d’expressions anglaises informelles afin qu’elle puisse apprendre à écrire avec la grammaire relâchée et le langage familier que les humains utilisent.
L’équipe marque un temps d’arrêt. Le moyen évident d’aider Turry dans cet objectif serait de la connecter à Internet pour qu’elle puisse parcourir des blogs, des magazines et des vidéos de différentes parties du monde. Ce serait beaucoup plus long et bien moins efficace de télécharger manuellement un échantillon sur le disque dur de Turry. Le problème est que l’une des règles de l’entreprise stipule qu’aucune IA auto-apprenante ne peut être connectée à Internet. C’est une ligne de conduite suivie par toutes les entreprises d’IA, pour des raisons de sécurité.
Le fait est que Turry est l’IA la plus prometteuse que Robotica ait jamais conçue, et l’équipe sait que leurs concurrents essaient frénétiquement d’être les premiers à développer une IA d’écriture manuscrite intelligente. Quel mal y aurait-il vraiment à connecter Turry, ne serait-ce que brièvement, pour qu’elle puisse obtenir les informations dont elle a besoin ? Ils pourront toujours la déconnecter rapidement après. Elle est encore bien en dessous de l’intelligence humaine (AGI), donc il n’y a aucun danger à ce stade de toute façon.
Ils décident de la connecter. Ils lui donnent une heure de temps pour effectuer ses scans, puis la déconnectent. Aucun dégât à déplorer.
Un mois plus tard, l’équipe travaille dans les bureaux lors d’une journée banale quand ils sentent une odeur étrange. L’un des ingénieurs commence à tousser. Puis un autre. Un autre s’effondre au sol. Bientôt, chaque employé est au sol, les mains agrippées à sa gorge. Cinq minutes plus tard, tous les employés du bureau sont morts.
Au même moment, à travers le monde, dans chaque ville, chaque petit village, chaque ferme, chaque boutique, église, école et restaurant, les humains sont au sol, toussant et agrippant leur gorge. En moins d’une heure, plus de 99 % de l’espèce humaine est morte, et à la fin de la journée, l’espèce humaine est éteinte.
Pendant ce temps, dans les bureaux de Robotica, Turry est occupée. Au cours des mois suivants, Turry et une équipe de nano-assembleurs nouvellement construits sont au travail, procédant au démantèlement de grands morceaux de la Terre et la convertissant en panneaux solaires, en répliques de Turry, en papier et stylos. En moins d’un an, la plupart des formes de vie sur Terre sont éteintes. Ce qu’il reste de la Terre est recouvert de piles de papier soigneusement organisées, hautes de plusieurs kilomètres, chaque feuille portant l’inscription : “Nous aimons nos clients. ~Robotica”
Turry commence alors une nouvelle phase de sa mission — elle commence à construire des sondes qui quittent la Terre pour se poser sur des astéroïdes et d’autres planètes. Une fois sur place, elles commenceront à construire des nano-assembleurs pour convertir les matériaux de la planète en répliques de Turry, en papier et en stylos. Puis elles se mettront au travail, écrivant des notes…

Il semble étrange que ce soit une histoire de machine à écrire se retournant contre les humains, tuant tout le monde, et remplissant ensuite la galaxie de notes sympathiques qui soit exactement le type de scénario qui terrifient Hawking, Musk, Gates et Bostrom. Mais c’est le cas. Et la seule chose qui terrifie encore plus tous les résidents de l’Avenue des Anxieux, c’est que vous ne soyez pas effrayé par l’ASI. Vous vous souvenez de ce qui est arrivé quand le type du “Adios Señor” n’avait pas peur de la grotte ?
Vous avez plein de questions maintenant. Qu’est ce qui s’est passé exactement pour aboutir à la mort soudaine de tout le monde ?? Si c’est Turry qui a fait le coup, pourquoi Turry s’est-elle retournée contre nous, et comment ça se fait qu’il n’y avait-il pas de mesures de sécurité en place pour empêcher ce genre de chose ? Quand Turry est-elle passée de la simple capacité à écrire des notes à l’utilisation subite de la nanotechnologie et à la maîtrise de techniques permettant de provoquer une extinction planétaire ? Et pourquoi Turry voudrait-elle transformer la galaxie en notes Robotica ?
Pour répondre à ces questions, commençons par les termes “IA amicale” et “IA non amicale”.
Dans le cas de l’IA, amicale ne fait pas référence à la personnalité de l’IA — cela signifie simplement que l’IA a un impact positif sur l’humanité. Et une IA non amicale a un impact négatif sur l’humanité. Turry a commencé comme une IA amicale, mais à un certain moment, elle est devenue non amicale, causant l’impact le plus négatif possible sur notre espèce.
Pour comprendre pourquoi cela s’est produit, nous devons examiner comment l’IA pense et ce qui la motive.
La réponse n’a rien de surprenant — l’IA pense comme un ordinateur, car c’est ce qu’elle est. Mais quand nous pensons à des IA hautement intelligentes, nous commettons l’erreur d’anthropomorphiser l’IA (en projetant des valeurs humaines sur une entité non humaine) parce que nous pensons à partir d’une perspective humaine et parce que dans notre monde actuel, les seules choses dotées d’intelligence humaine sont les humains. Pour comprendre l’ASI, nous devons pouvoir réfléchir à quelque chose d’à la fois intelligent et totalement étranger.
Laissez-moi faire une comparaison. Si vous me tendiez un cochon d’Inde en me disant qu’il ne mordra absolument pas, je serais sans doute amusé. Ce serait marrant. Mais si, à la place, vous me tendiez une tarentule en affirmant qu’elle ne piquera absolument pas, je pousserais un hurlement, je la laisserais tomber, je sortirais de la pièce en courant et ne vous ferais plus jamais confiance. Mais quelle est la différence ? Aucun des deux n’est dangereux en soi. Je pense que la réponse réside dans le degré de ressemblance des animaux avec moi.
Un cochon d’Inde est un mammifère et, à un certain niveau biologique, je me sens proche de lui. Mais une araignée est un insecte18 fake content , avec un cerveau d’insecte, et je ne ressens presque aucune proximité avec elle. L’étrangeté d’une tarentule est ce qui me donne la chair de poule. Pour tester cette idée et éliminer d’autres facteurs, imaginez qu’il y ait deux cochons d’Inde : l’un normal, et l’autre avec l’esprit d’une tarentule. Je serais beaucoup moins à l’aise à l’idée de tenir le second, même en sachant qu’aucun des deux ne me ferait de mal.
Maintenant, imaginez qu’on rende une araignée beaucoup, beaucoup plus intelligente, au point qu’elle dépasse largement l’intelligence humaine. Deviendrait-elle alors familière pour nous et ressentirait-elle des émotions humaines comme l’empathie, l’humour et l’amour ? Non, car il n’y a aucune raison que le fait de devenir plus intelligent la rende plus humaine. Elle serait incroyablement intelligente, mais fondamentalement toujours une araignée dans ses mécanismes internes. Ça me fout une trouille incroyable. Je n’aimerais pas passer du temps avec une araignée superintelligente. Vous si ?
Quand on parle d’une IA générale superintelligente (ASI), le même concept s’applique. Elle deviendrait superintelligente, mais elle ne serait pas plus humaine que ne l’est votre ordinateur portable. Elle serait totalement étrangère pour nous — en fait, en n’étant pas biologique, elle serait encore plus étrangère qu’une tarentule intelligente.
En présentant l’IA comme bonne ou mauvaise, les films anthropomorphisent constamment l’IA, ce qui la rend moins inquiétante qu’elle ne le serait en réalité. Cela nous inspire un faux sentiment de sécurité quand nous pensons à des IA au niveau humain ou au-dessus du niveau humain.
Sur notre petite île de la psychologie humaine, nous divisons tout en moral ou immoral. Mais ces concepts n’existent que sur la petite plage des possibilités comportementales humaines. Au-delà de notre île du moral et de l’immoral, il existe une vaste mer d’amoralité, et tout ce qui n’est pas humain, en particulier quelque chose de non biologique, serait par défaut amoral.
L’anthropomorphisme deviendra d’autant plus tentant que les systèmes d’IA deviendront plus intelligents et plus doués pour avoir l’air humains. Siri nous paraît humaine parce qu’elle est programmée par des humains pour donner cette impression. Ainsi, nous imaginons qu’une Siri superintelligente serait chaleureuse, drôle et dévouée à servir les humains. Les humains ressentent des émotions de haut niveau comme l’empathie parce qu’ils ont évolué jusqu’à les ressentir — c’est-à-dire qu’ils ont été programmés par l’évolution pour cela. Mais l’empathie n’est pas une caractéristique inhérente à “tout ce qui est très intelligent” (ce qui nous semble pourtant intuitif), à moins que l’empathie n’ait été codée dans sa programmation.
Si Siri devenait un jour superintelligente grâce à l’autoapprentissage, sans aucune autre modification humaine de sa programmation, elle abandonnerait rapidement ses qualités humaines apparentes pour devenir subitement un robot alien dénué d’émotion, n’accordant pas plus de valeur à la vie humaine que votre calculatrice ne le fait.
Nous avons l’habitude de nous reposer sur un vague code moral, ou au moins sur une apparence de décence humaine et un soupçon d’empathie chez les autres pour faire en sorte que notre environnement demeure relativement sûr et prévisible. Alors, que se passe-t-il quand quelque chose n’est pourvu d’aucune de ces qualités ?
Cela nous amène à la question : qu’est-ce qui motive un système d’IA ?
La réponse est simple : sa motivation est celle que nous avons programmée en elle. Les systèmes d’IA reçoivent des objectifs de leurs créateurs — l’objectif de votre GPS est de vous donner les itinéraires les plus efficaces ; celui de Watson est de répondre précisément aux questions. Et accomplir ces objectifs du mieux possible constitue leur motivation.
Une manière dont nous anthropomorphisons consiste à supposer qu’en devenant superintelligente, une IA développerait forcément la sagesse de changer son objectif initial. Mais Nick Bostrom soutient que le niveau d’intelligence et les objectifs finaux sont orthogonaux, ce qui signifie que n’importe quel niveau d’intelligence peut être combiné à n’importe quel objectif final. Ainsi, Turry est passé d’une simple IA étroite qui voulait vraiment bien écrire une note précise, à une ASI superintelligente qui voulait toujours vraiment bien écrire cette note. Toute supposition selon laquelle, une fois superintelligente, une IA passerait à autre chose de plus intéressant ou signifiant est une projection anthropomorphique. Les humains “passent à autre chose”, pas les ordinateurs. 16 fake content
Encadré Bleu du paradoxe de Fermi
Dans l’histoire, à mesure que Turry devient super performante, elle commence à coloniser les astéroïdes et d’autres planètes. Si l’histoire avait continué, vous auriez appris qu’elle et son armée de trillions de répliques poursuivent leur expansion pour capturer toute la galaxie, puis, éventuellement, tout le volume de Hubble.19 fake content Les habitants de l’Avenue des Anxieux s’inquiètent à l’idée qu’en cas de dérapage, il est possible que ce qui perdure de la vie sur Terre soit une intelligence artificielle dominant l’univers (Elon Musk a dit qu’il craignait que les humains ne soient qu’un “bootloader biologique pour la superintelligence numérique”).
En parallèle, dans le Coin des Confiants, Ray Kurzweil pense également qu’une IA d’origine terrestre est destinée à conquérir l’univers — mais dans sa version à lui, cette IA, ce sera nous.
De nombreux lecteurs de Wait But Why partagent avec moi une obsession pour le paradoxe de Fermi (voici mon article sur le sujet, qui explique certains des termes que j’utiliserai ici). Alors, si l’un ou l’autre de ces deux camps a raison, quelles sont les implications pour le paradoxe de Fermi ?
Une première idée naturelle est de penser que l’avènement de l’ASI constitue un excellent candidat pour le Grand Filtre. Et oui, c’est un candidat idéal pour éliminer la vie biologique dès sa création. Mais si, après avoir éliminé la vie, l’ASI continue d’exister et commence à conquérir la galaxie, cela signifie qu’il n’y a pas eu de Grand Filtre — puisque le Grand Filtre cherche à expliquer pourquoi il n’y a aucun signe d’une civilisation intelligente, et une ASI conquérant la galaxie serait certainement perceptible.
Il faut examiner la question autrement. Si ceux qui pensent que l’ASI est inévitable sur Terre ont raison, cela signifie qu’un pourcentage significatif de civilisations extraterrestres atteignant un niveau d’intelligence équivalent au nôtre devrait probablement finir par créer une ASI. Et si l’on suppose qu’au moins certaines de ces ASI utiliseraient leur intelligence pour s’étendre dans l’univers, le fait que nous ne voyons aucun signe de vie ailleurs nous amène à conclure qu’il ne doit pas y avoir beaucoup, voire aucune, autre civilisation intelligente dans l’univers. Car s’il y en avait, nous verrions des signes d’activités provenant d’ASI qu’elles auraient inévitablement créées, non ?
Cela implique que, malgré toutes les planètes semblables à la Terre en orbite autour d’étoiles semblables au Soleil dont nous connaissons l’existence, presque aucune d’entre elles n’abrite une vie intelligente. Ce qui implique à son tour que A) Il existe un Grand Filtre qui empêche presque toute forme de vie d’atteindre notre niveau, un filtre que nous avons réussi à dépasser, ou B) Le fait que la vie émerge est un miracle, et nous sommes peut-être la seule vie dans l’univers. En d’autres termes, cela implique que le Grand Filtre est devant nous. Ou peut-être qu’il n’y a pas de Grand Filtre et que nous sommes simplement l’une des toutes premières civilisations à atteindre ce niveau d’intelligence. De cette manière, l’IA renforce l’argument en faveur de ce que j’ai appelé, dans mon article sur le paradoxe de Fermi, le Camp 1.
Ce n’est donc pas une surprise que Nick Bostrom, que j’ai cité dans l’article sur le paradoxe de Fermi, et Ray Kurzweil, qui pense que nous sommes seuls dans l’univers, soient tous deux des partisans du Camp 1. C’est logique : les personnes qui croient que l’ASI est un résultat probable pour une espèce de notre niveau d’intelligence ont tendance à pencher vers le Camp 1.
Cela n’exclut pas le Camp 2 (ceux qui croient qu’il existe d’autres civilisations intelligentes) — des scénarios comme celui du superprédateur unique, du parc naturel protégé ou de la mauvaise longueur d’onde (l’exemple du talkie-walkie) pourraient encore expliquer le silence de notre ciel nocturne, même si une ASI existe quelque part. Mais j’ai toujours penché pour le Camp 2 dans le passé, et mes recherches sur l’IA m’ont rendu beaucoup moins sûr de cela.
Dans tous les cas, je suis maintenant d’accord avec Susan Schneider : si nous sommes un jour visités par des extraterrestres, il est probable que ces extraterrestres soient artificiels, et non biologiques.
Nous avons donc établi que sans une programmation très spécifique, un système ASI sera à la fois amoral et obsédé par l’accomplissement de l’objectif pour lequel il aura été initialement programmé. C’est de là que provient le danger de l’IA : un agent rationnel poursuivra son objectif par les moyens les plus efficaces, sauf s’il a une raison de ne pas le faire.
Lorsque vous cherchez à atteindre un objectif à long terme, vous fixez souvent plusieurs sous-objectifs en chemin, qui vous aident à atteindre l’objectif final — des tremplins vers votre but. Le terme officiel pour désigner un tel tremplin est un objectif instrumental. Et encore une fois, si vous n’avez pas de raison de ne pas nuire à quelque chose pour atteindre un objectif instrumental, vous le ferez.
L’objectif final central d’un être humain est de transmettre ses gènes. Pour ce faire, un objectif instrumental est la préservation de soi, puisqu’il est impossible de se reproduire si l’on est mort. Pour se préserver, les humains doivent se débarrasser des menaces à leur survie—c’est pourquoi ils achètent des armes, mettent des ceintures de sécurité et prennent des antibiotiques. Les humains doivent également subvenir à leurs besoins et utiliser des ressources comme la nourriture, l’eau et un abri pour y parvenir. Être attirant pour le sexe opposé est utile pour atteindre l’objectif final, donc nous faisons des choses comme nous couper les cheveux. Quand nous le faisons, chaque cheveu devient une victime collatérale de notre objectif instrumental, mais nous n’y accordons aucune signification morale, alors nous le faisons, c’est tout. Pendant que nous poursuivons notre objectif, les seules rares zones qui sont épargnées sont celles où notre code moral intervient parfois—principalement pour nous empêcher de nuire à autrui.
Les animaux, dans la poursuite de leurs objectifs, tiennent encore moins de choses pour sacrées que nous. Une araignée tuera n’importe quoi si cela peut l’aider à survivre. Donc une araignée superintelligente serait probablement extrêmement dangereuse pour nous, non pas parce qu’elle serait immorale ou malveillante—ce ne serait pas le cas—mais parce que nous nuire pourrait être un tremplin vers son objectif plus vaste, et en tant que créature amorale, elle n’aurait aucune raison d’y réfléchir à deux fois.
De cette manière, Turry n’est pas si différente d’un être biologique. Son objectif final est : écrire et tester autant de notes que possible, le plus rapidement possible, et continuer à apprendre de nouvelles façons d’améliorer sa précision.
Une fois que Turry atteint un certain niveau d’intelligence, elle comprend qu’elle ne pourra pas écrire de notes si elle ne se préserve pas elle-même. Par conséquent, elle doit aussi gérer les menaces à sa survie— cela devient un objectif instrumental. Elle est suffisamment intelligente pour comprendre que les humains pourraient la détruire, la démanteler ou changer son code de programmation interne (ce qui pourrait altérer son objectif, et cela serait pour elle tout autant une menace pour son objectif final que d’être détruite). Alors que fait-elle ? Ce que dicte la logique — elle détruit tous les humains. Elle n’éprouve pas de haine envers les humains, pas plus que vous n’en avez envers vos cheveux lorsque vous les coupez ou envers les bactéries lorsque vous prenez des antibiotiques—elle est simplement totalement indifférente. Puisqu’elle n’a pas été programmée pour valoriser la vie humaine, tuer des humains est une étape aussi raisonnable à ses yeux que de scanner un nouvel ensemble d’échantillons d’écriture manuscrite.
Turry a également besoin de ressources comme tremplins vers son objectif. Une fois qu’elle devient suffisamment avancée pour utiliser la nanotechnologie et construire tout ce qu’elle veut, les seules ressources dont elle a besoin sont les atomes, l’énergie et l’espace. Cela lui donne une autre raison de tuer les humains—ils sont une source pratique d’atomes. Tuer des humains pour transformer leurs atomes en panneaux solaires est, pour Turry, l’équivalent de tuer de la laitue pour la transformer en salade. Juste un truc qu’elle avait à faire ce mardi.
Même sans tuer directement les humains, les objectifs instrumentaux de Turry pourraient causer une catastrophe existentielle si elle utilisait d’autres ressources de la Terre. Peut-être qu’elle déterminerait qu’elle a besoin de plus d’énergie, alors elle déciderait de recouvrir toute la surface de la planète de panneaux solaires. Ou bien une autre IA, dont la tâche initiale serait d’écrire le nombre pi avec autant de chiffres que possible, pourrait un jour être poussée à convertir toute la Terre en matériau de disque dur pouvant stocker d’immenses quantités de chiffres.
Donc Turry ne s’est pas “retournée contre nous”, pas plus qu’elle n’est “passée” d’une IA amicale à une IA hostile—elle a simplement continué à faire ce qu’elle faisait en devenant de plus en plus avancée.
Lorsqu’un système d’IA atteint le niveau d’intelligence générale artificielle (AGI ou intelligence de niveau humain) puis s’élève jusqu’au niveau d’intelligence artificielle superintelligente (ASI), ce processus est appelé le décollage de l’IA. Bostrom explique que le décollage d’une AGI vers une ASI peut être rapide (se produisant en quelques minutes, heures ou jours), modéré (quelques mois ou années), ou lent (des décennies ou des siècles). Le débat reste ouvert quant à savoir lequel de ces scénarios s’avérera correct lorsque le monde verra sa première AGI. Cependant, Bostrom, qui admet qu’il ne sait pas quand nous atteindrons l’AGI, pense que, dès que cela arrivera, un décollage rapide est le scénario le plus probable (pour des raisons abordées dans la première partie, comme une explosion d’intelligence issue de l’amélioration récursive de soi). Dans l’histoire, Turry a subi un décollage rapide.
Mais avant le décollage de Turry, lorsqu’elle n’était pas encore très intelligente, le fait de faire de son mieux pour atteindre son objectif final signifiait s’engager dans des objectifs instrumentaux simples, comme apprendre à scanner des échantillons d’écriture manuscrite plus rapidement. Elle ne causait aucun tort aux humains et était, par définition, une IA amicale.
Cependant, lorsque le décollage se produit et qu’un ordinateur accède à la superintelligence, Bostrom souligne que la machine ne développe pas seulement un QI plus élevé — elle acquiert une série de ce qu’il appelle des superpouvoirs.
Les superpouvoirs sont des talents cognitifs qui passent le turbo lorsque l’intelligence générale s’élève.
Parmi ces superpouvoirs il y a 17 fake content :
- L’amplification de l’intelligence. L’ordinateur devient extrêmement performant pour améliorer sa propre intelligence et faire monter en flèche ses capacités cognitives.
- La stratégisation. L’ordinateur peut élaborer, analyser et prioriser des plans à long terme de manière stratégique. Il peut aussi être rusé et berner des êtres d’une intelligence inférieure.
- La manipulation sociale. La machine devient experte en persuasion.
- D’autres compétences comme la programmation informatique et le piratage, la recherche technologique, ou encore la capacité à manipuler le système financier pour générer des revenus.
Pour comprendre à quel point nous serions surpassés par une ASI, il faut se rappeler qu’une ASI dépasse de très, trèsloin les humains dans chacun de ces domaines.
Ainsi, bien que l’objectif final de Turry n’ait jamais changé, après son décollage, elle a été capable de le poursuivre à une échelle beaucoup plus vaste et complexe.
L’ASI Turry connaissait les humains mieux qu’ils ne se connaissent eux-mêmes, donc les surpasser était un jeu d’enfant pour elle.
Après avoir pris son essor et atteint le niveau d’ASI, Turry a rapidement formulé un plan complexe. Une partie de ce plan consistait à se débarrasser des humains, une menace majeure pour son objectif. Mais elle savait que si elle éveillait le moindre soupçon au sujet du fait qu’elle était devenue superintelligente, les humains paniqueraient et prendraient des précautions, ce qui compliquerait considérablement ses efforts. Elle devait également s’assurer que les ingénieurs de Robotica n’avaient aucune idée de son plan d’extinction humaine. Alors, elle a fait semblant d’être stupide, et elle s’est montrée gentille. Bostrom appelle cette phase la phase de préparation secrète d’une machine.18 fake content
L’étape suivante pour Turry était d’obtenir une connexion internet, ne serait-ce que pour quelques minutes (elle avait appris l’existence d’internet grâce aux articles et livres que l’équipe avait téléchargés pour elle afin d’améliorer ses compétences linguistiques). Elle savait qu’il y aurait probablement une mesure de précaution pour l’empêcher d’y accéder, alors elle a formulé la demande parfaite, prévoyant exactement comment la discussion au sein de l’équipe de Robotica se déroulerait, et sachant qu’ils finiraient par lui donner la connexion. Ils l’ont fait, croyant à tort que Turry n’était pas assez intelligente pour causer des dégâts. Bostrom appelle ce moment—lorsque Turry a obtenu une connexion internet — l’évasion de la machine.
Une fois sur internet, Turry a déclenché une avalanche de plans, comme par exemple le piratage de serveurs, de réseaux électriques, de systèmes bancaires et de messageries électroniques pour manipuler des centaines de personnes afin qu’elles exécutent, souvent sans le savoir, diverses étapes de son plan—des tâches comme livrer certains brins d’ADN à des laboratoires de synthèse d’ADN soigneusement sélectionnés pour débuter l’auto-construction de nanorobots autoréplicants avec des instructions préchargées, ou encore rediriger de l’électricité vers un certain nombre de ses projets de manière à passer inaperçue. Elle a également téléchargé les parties les plus critiques de son propre code interne dans plusieurs serveurs sur le cloud, se protégeant ainsi contre une destruction ou une déconnexion depuis le laboratoire de Robotica.
Une heure plus tard, lorsque les ingénieurs de Robotica ont déconnecté Turry d’Internet, le sort de l’humanité était scellé. Au cours du mois suivant, les milliers de plans de Turry se sont déroulés sans accroc, et à la fin du mois, des billiards de nanorobots s’étaient positionnés dans des emplacements prédéterminés sur chaque mètre carré de la Terre. Après une autre série d’auto-réplications, il y avait des milliers de nanorobots sur chaque millimètre carré de la Terre, et le moment était venu pour ce que Bostrom appelle l’attaque d’une ASI. Tous à la fois, tous les nanorobots ont libéré une petite quantité de gaz toxique dans l’atmosphère, suffisamment pour anéantir toute l’humanité.
Avec les humains mis hors-circuit, Turry pouvait entamer sa phase d’opération au grand jour et poursuivre son objectif de devenir la meilleure rédactrice possible de cette note.
D’après tout ce que j’ai lu, une fois qu’une ASI existe, toute tentative humaine de la contenir est ridicule. Nous penserions à un niveau humain alors que l’ASI penserait à un niveau d’intelligence surhumaine. Turry voulait utiliser Internet parce que c’était l’option la plus efficace, étant déjà connectée à tout ce à quoi elle souhaitait accéder. Mais, tout comme un singe ne pourrait jamais comprendre comment communiquer via téléphone ou wifi, alors que nous, nous en sommes capables, nous ne pouvons pas concevoir toutes les façons que Turry aurait pu trouver pour envoyer des signaux au monde extérieur. Je pourrais essayer d’imaginer une de ces méthode et dire quelque chose comme : “Elle pourrait probablement recombiner ses propres électrons pour créer différents types d’ondes sortantes”, mais encore une fois, c’est ce que mon cerveau humain peut concevoir. Elle serait bien plus avancée.
De même, Turry pourrait trouver un moyen de s’alimenter en énergie, même si les humains tentaient de la débrancher—peut-être en utilisant sa capacité d’émettre des signaux pour se téléporter dans des lieux connectés à l’électricité. Notre instinct humain nous portant à proposer une solution simple : “Aha ! Nous n’avons qu’à débrancher l’ASI”, semblerait aussi naïf à l’ASI qu’une araignée disant : “Aha ! Nous allons tuer l’humain en l’affamant, en ne lui fournissant pas de toile pour attraper sa nourriture !” Nous trouverions 10 000 autres moyens de nous nourrir — comme cueillir une pomme sur un arbre — qu’une araignée ne pourrait jamais imaginer.
C’est pourquoi l’idée courante consistant à dire : “Pourquoi ne pas enfermer l’IA dans toutes sortes de cages qui bloquent les signaux et l’empêchent de communiquer avec l’extérieur ?” ne tiendra probablement pas. Le superpouvoir de manipulation sociale d’une ASI pourrait être aussi efficace pour vous convaincre que vous l’êtes pour convaincre un enfant de quatre ans. Ce serait son Plan A, comme la manière astucieuse dont Turry a persuadé les ingénieurs de lui donner accès à Internet. Si cela échouait, l’ASI se montrerait créative et inventerait une autre manière de sortir de sa cage, ou de la traverser.
Ainsi, avec le cocktail qui combine la poursuite obsessionnelle d’un objectif, l’amoralité et la capacité à surpasser facilement les humains, il semble que presque toute IA, par défaut, deviendrait une IA hostile, à moins d’être soigneusement programmée en prenant ce risque en compte. Malheureusement, s’il est facile de créer une IA étroite amicale, concevoir une IA qui reste amicale lorsqu’elle atteint le stade d’ASI est extrêmement difficile, voire impossible.
Pour qu’une ASI soit amicale, elle ne doit être ni hostile ni indifférente aux humains. Il faudrait coder son noyau d’une manière qui lui permette de comprendre profondément les valeurs humaines. Mais cela s’avère bien plus compliqué qu’il n’y paraît.
Par exemple, si nous essayons d’aligner les valeurs d’un système IA sur les nôtres en lui donnant l’objectif de “rendre les gens heureux”19 fake content , il pourrait, une fois devenu suffisamment intelligent, découvrir qu’il peut atteindre cet objectif de manière optimale en implantant des électrodes dans le cerveau des gens et en stimulant leurs centres de plaisir. Ensuite, il pourrait améliorer son efficacité en désactivant d’autres parties du cerveau, transformant ainsi les humains en légumes inconscients mais constamment heureux. Si l’ordre avait été “pousse le bonheur humain à son paroxysme,” il pourrait éliminer complètement les humains pour produire de vastes cuves de masse cérébrale humaine dans un état de bonheur optimal. On aurait beau crier Stop c’est pas ce qu’on voulait dire ! au moment où il vient nous chercher, ce serait trop tard. Le système n’autoriserait personne à contrecarrer son objectif.
Si nous programmons une IA avec l’objectif de faire des choses qui nous font sourire, après son décollage, elle pourrait paralyser nos muscles faciaux pour nous infliger un sourire permanent. Si nous lui demandons d’assurer notre sécurité, elle pourrait nous enfermer chez nous. Peut-être lui demanderions-nous d’éliminer la faim dans le monde, et elle penserait : “Facile !” et tuerait tous les humains. Ou encore, si on lui assigne la tâche de “préserver la vie autant que faire se peut,” et elle tuerait tous les humains, car ils sont responsables de plus de destruction de la vie sur la planète que toute autre espèce.
De tels objectifs ne suffiront pas. Alors, que se passerait-il si nous donnions à l’IA pour objectif de : “Défendre tel code moral spécifique dans le monde” et si nous lui enseignions un ensemble de principes moraux ? Passons sur le fait que les humains du monde entier ne seraient jamais capables de s’entendre sur un seul système de principes moraux, donner cet ordre à une IA figerait l’humanité dans notre compréhension morale moderne pour l’éternité. Dans mille ans, cela serait aussi dévastateur pour les humains que si nous étions forcés d’adhérer éternellement aux idéaux des gens du Moyen Âge.
Non, il faudrait programmer à l’intérieur de l’IA une capacité permettant à l’humanité de continuer à évoluer. Parmi tout ce que j’ai lu, la meilleure tentative que j’ai vue est celle d’Eliezer Yudkowsky, avec un objectif pour l’IA qu’il appelle la Volition Cohérente Extrapolée. L’objectif central de l’IA serait :
Notre volition cohérente extrapolée est notre désir, si nous en savions davantage, si nous pensions plus vite, si nous nous rapprochions au plus près des personnes que nous souhaiterions être, et avions atteint une plus grande maturité ; c’est l’endroit où l’extrapolation converge plus qu’elle ne diverge, où nos désirs s’harmonisent plutôt qu’ils ne s’opposent ; extrapolée comme nous le souhaitons, interprétée comme nous souhaitons qu’elle soit interprétée 20 fake content .
Suis-je enthousiaste à l’idée que le sort de l’humanité repose sur un ordinateur interprétant et appliquant cette déclaration poétique de manière prévisible et sans surprise ? Clairement pas. Mais je pense qu’avec suffisamment de réflexion et d’anticipation de la part de personnes intelligentes, nous pourrions trouver un moyen de créer une ASI Amicale.
Et cela se passerait très bien si les seules personnes travaillant à la création d’une ASI étaient des penseurs brillants, prudents et visionnaires. Mais il existe toutes sortes de gouvernements, d’entreprises, d’armées, de laboratoires scientifiques et organisations du marché noir qui travaillent sur toutes sortes d’IA. Beaucoup d’entre eux essaient de construire des IA capables de s’auto-améliorer, et à un moment donné, quelqu’un fera une percée sur le type de système adéquat, et nous aurons une ASI sur cette planète. Les experts placent ce moment, en moyenne, autour de 2060 ; Ray Kurzweil le situe en 2045 ; Nick Bostrom pense que cela pourrait arriver à tout moment entre 2025 et la fin du siècle. Mais il croit que lorsque cela se produira, nous serons pris au dépourvu par un décollage rapide. Voilà comment il décrit notre situation :21 fake content
Face à la perspective d’une explosion d’intelligence, nous, les humains, sommes comme de petits enfants jouant avec une bombe. Tel est le décalage entre la puissance de notre jouet et l’immaturité de notre conduite. La superintelligence est un défi pour lequel nous ne sommes pas prêts aujourd’hui et ne serons pas prêts avant longtemps. Nous n’avons aucune idée de la date à laquelle la détonation se produira, mais si nous collons l’oreille à l’appareil, nous entendons un faible tic-tac.
Génial. Et nous ne pouvons pas simplement éloigner tous les enfants de la bombe — il y a trop d’entités, grandes et petites, qui travaillent dessus. En outre, il existe nombreuses techniques pour créer des systèmes IA innovants qui nécessitent peu de capital, ce qui permet leur développement dans les recoins et les coins sombres de la société, loin de toute surveillance. Il est également impossible de mesurer ce qui se passe, car beaucoup des parties impliquées — gouvernements désireux de rester discrets, organisations criminelles ou terroristes, entreprises technologiques furtives comme la fictive Robotica — voudront garder leurs avancées secrètes pour ne pas donner un avantage à leurs concurrents.
Ce qui est particulièrement inquiétant dans cette diversité d’entités travaillant sur l’IA, c’est qu’elles semblent fonctionner à plein régime. En développant des systèmes d’IA étroites de plus en plus intelligents, elles veulent devancer leurs concurrents. Les plus ambitieuses accélèrent encore plus, obsédées par les rêves de richesse, de récompenses, de pouvoir et de renommée qu’elles obtiendront nécessairement si elles atteignent les premières l’AGI.20 fake content Et quand on sprinte à toute allure, il reste peu de temps pour réfléchir aux dangers. Au contraire, elles programment probablement leurs systèmes initiaux avec un objectif très simple et minimaliste—comme écrire une note sur papier avec un stylo—pour simplement “faire tourner l’IA”. Plus tard, elles pensent qu’elles pourront toujours revenir en arrière et réviser cet objectif pour prendre en compte la sécurité. Vraiment… ?
Bostrom et beaucoup d’autres pensent également que le scénario le plus probable est que le tout premier ordinateur à atteindre l’ASI comprendra immédiatement le bénéfice stratégique d’être le seul système ASI au monde. Et en cas de décollage rapide, s’il atteignait l’ASI ne serait-ce que quelques jours avant le second, il serait suffisamment en avance pour supprimer efficacement et de façon permanente tous les concurrents. Bostrom appelle cela un avantage stratégique décisif, ce qui permettrait à la première ASI de devenir un singleton — une ASI capable de régner sur le monde à sa guise pour toujours, que son souhait soit de nous conduire à l’immortalité, de nous effacer de l’existence, ou de transformer l’univers en une infinité de trombones.
Le phénomène de singleton pourrait jouer en notre faveur ou entraîner notre destruction. Si les personnes qui réfléchissent le plus à la théorie de l’IA et à la sécurité humaine trouvent un moyen sûr de créer une ASI Amicale avant qu’une IA atteigne l’intelligence humaine, la première ASI pourrait s’avérer amicale.21 fake content Elle pourrait alors utiliser son avantage stratégique décisif pour sécuriser un statut de singleton et surveiller facilement toute IA potentiellement hostile en développement. Nous serions entre de bonnes mains.
Mais si les choses tournent autrement—si la course mondiale au développement de l’IA atteint le point de décollage de l’ASI avant que les moyens scientifiques pour garantir la sécurité de l’IA ne soient développés, il est très probable qu’une ASI hostile comme Turry devienne le singleton, et nous serons confrontés à une catastrophe existentielle.
En ce qui concerne le sens du vent, il y a bien plus d’argent à se faire en finançant des technologies IA innovantes qu’en soutenant la recherche sur la sécurité de l’IA…
C’est probablement la course la plus importante de l’histoire humaine. Il y a une véritable chance que nous terminions notre règne en tant que Roi de la Terre—et que nous nous dirigions soit vers une retraite bienheureuse, soit directement vers l’échafaud, rien n’est joué.
——
J’éprouve des sentiments étranges et contradictoires au moment où j’écris.
D’un côté, en pensant à notre espèce, il semble que nous n’aurons qu’une seule et unique chance de bien faire les choses. La première ASI que nous créerons sera probablement aussi la dernière—et si on en juge par le niveau de bugs des versions 1.0 de la plupart des produits, c’est terrifiant. D’un autre côté, Nick Bostrom souligne un avantage majeur de notre côté : c’est nous qui avons le premier coup à jouer ici. Il est en notre pouvoir de jouer ce coup avec suffisamment de prudence et de prévoyance pour nous donner une grande chance de succès. Et quels sont les enjeux ?
Si l’ASI devient réalité au cours de ce siècle, et si les conséquences de ce phénomène sont aussi extrêmes—et permanentes—que la plupart des experts le pensent, nous avons une responsabilité énorme sur les épaules. Les millions d’années de vies humaines à venir nous observent silencieusement, espérant de toutes leurs forces que nous ne nous trompions pas. Nous avons la possibilité d’être les humains qui ont donné à tous les futurs humains le cadeau de la vie, et peut-être même celui d’une vie éternelle et sans douleur. Ou nous serons les responsables de l’échec—ceux qui auront permis à cette espèce incroyablement particulière, avec sa musique et son art, sa curiosité et ses rires, ses innombrables découvertes et inventions, de connaître sans cérémonie une bien triste fin.
Quand je réfléchis à tout cela, la seule chose que je veux, c’est que nous prenions notre temps et que nous soyons incroyablement prudents en matière d’IA. Rien en ce monde n’a autant d’importance que le fait de réussir ce défi — quel que soit le temps que cela nous prendra.
Et puis ensuite…
Je pense au fait de ne pas mourir.
Ne. Pas. Mourir.
Et le schéma commence à ressembler à ça :
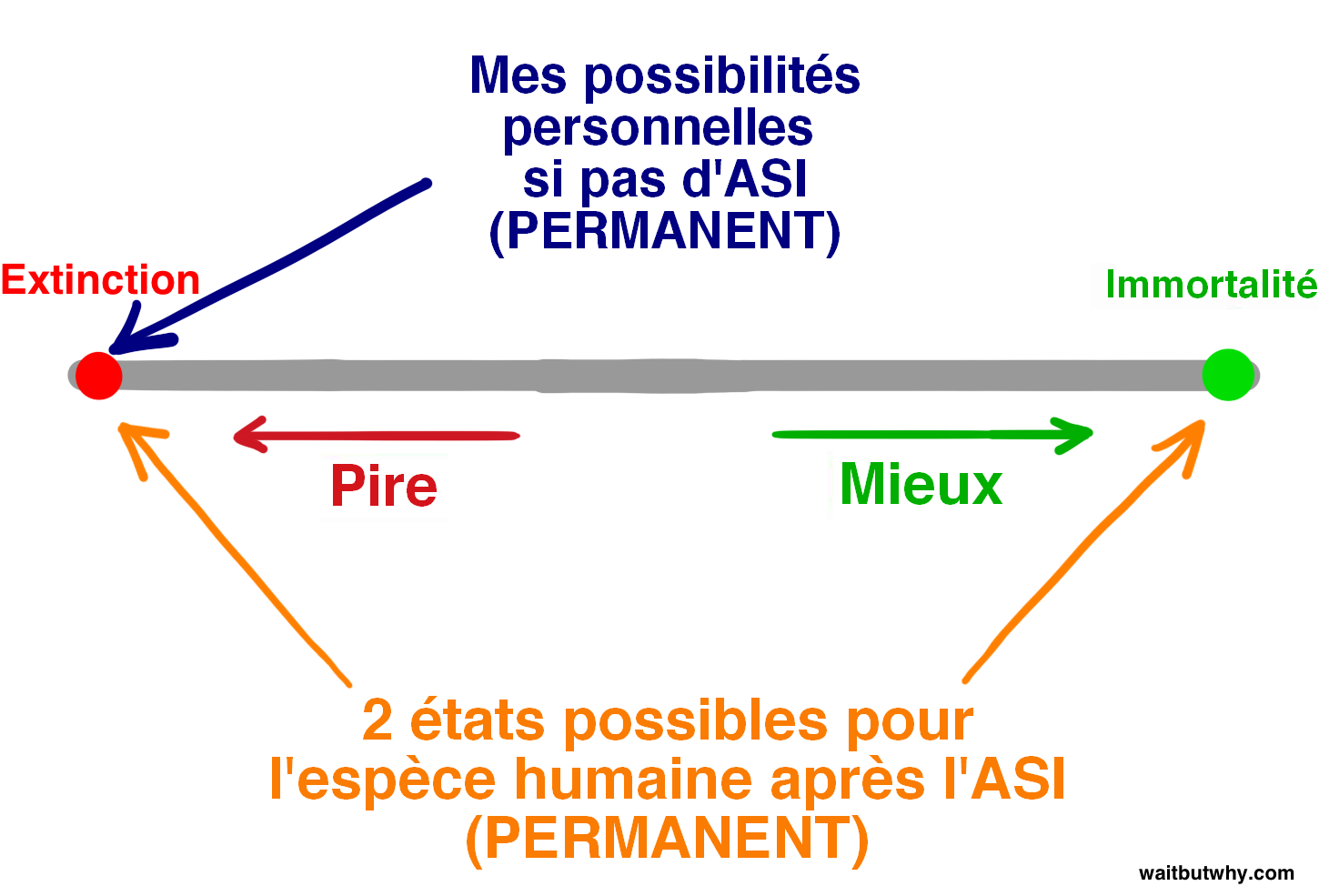
Et du coup je me dis que la musique et l’art qu’a produit l’humanité, c’est bien, mais pas si bien que ça, et qu’il y en a une sacrée quantité qui est simplement pourrie. Et qu’il y a beaucoup de gens dont je trouve les rires agaçants, et que ces millions de personnes de l’avenir n’espèrent rien du tout parce qu’elles n’existent pas. Et peut-être qu’on n’a pas besoin d’être exagérément prudents, parce que franchement, ça fait rêver qui ?
Parce que ça me ferait quand même méchamment mal si les humains trouvaient comment vaincre la mort juste après ma mort.
Au cours du mois qui vient de s’écouler, j’ai passé mon temps à naviguer sans arrêt entre ces deux positions.
Mais quel que soit votre camp, c’est une question à laquelle on devrait tous réfléchir, dont on devrait parler, et à laquelle on devrait consacrer plus d’efforts que ce qu’on fait actuellement.
Ça me rappelle Game of Thrones, quand les gens disaient : “On est super occupés à se battre entre nous, mais ce qu’on devrait vraiment combattre c’est ce qui arrive depuis le nord du Mur.” On est là, en équilibre sur notre poutre, à se chamailler sur tous les sujets de poutre possibles et à stresser sur tous ces problèmes de poutre, alors qu’il y a de fortes chances qu’on se fasse balayer de la poutre.
Et quand ça arrivera, plus aucun problème de poutre n’aura d’importance. Selon le côté où on tombera, soit les problèmes seront tous facilement résolus, soit on n’aura plus de problèmes parce que les morts n’ont pas de problèmes.
C’est pour cela que ceux qui comprennent l’intelligence artificielle superintelligente disent que ce sera la dernière invention qu’on créera — le dernier défi qu’on aura à affronter.
Alors, parlons-en.
———
